
In-depth research on AI architecture: The era of storage and connectivity?
- BedRock

- Mar 30
- 20 min read
From Neuroscience to Capex Structure: The AI Hardware Value Chain is Being Restructured
01 Should the Future of AI Be Driven by Storage and Connectivity?
02 From Training to Agent: Four Stages of Evolution
03 The Memory Wall and KV Cache in the Agent Era
04 Efficiency Improvement, Supply and Demand Patterns, and Cycle Positioning
05 Investment Implications and Industry Chain Mapping
06 Summary
Should the future of AI be dominated by storage and connectivity, with computing accounting for only a small portion?
Neuroscientists study the brain, computer architects study chips, and engineers measure data centers—researchers from three completely different fields, starting from their respective points, have all pointed to the same conclusion: the bottleneck and main energy consumption of AI systems lies in data movement (storage access + interconnection communication), rather than arithmetic computation itself.
William B. Levy and Victoria G. Calvert of the University of Virginia published a paper in the Proceedings of the National Academy of Sciences (PNAS) with the straightforward title: "Communication consumes 35 times more energy than computation in the human cortex."
To understand this research, it's essential to first understand their definitions of "computation" and "communication." In the brain, "computation" refers to a single neuron making inferences and predictions about local environmental variables based on synaptic input signals it receives—similar to a miniature sensor analyzing the data it receives. "Communication," on the other hand, is the process of transmitting these inferences from one neuron to another—including the conduction of action potentials along axons (signals propagating in wires), the release of neurotransmitters from synaptic vesicles (transmitting chemical signals between two wires), and the subsequent recovery of ions to restore the potential difference (recharging the battery).
The total power consumption of the human brain is approximately 17W (based on PET scan data, correcting the previously cited rough estimate of 20W). After deducting heat dissipation losses (8.89W), only about 4.94 ATP-W is available for actual brain function. Of this, only about 0.1W is allocated to cortical computation—communication consumes 35 times the energy of computation.
In a commentary accompanying PNAS, Balasubramanian summarizes: The core optimization goal of brain evolution is not maximizing computational speed, but rather optimizing communication efficiency to support distributed computing under strict energy constraints. The brain has approximately 200 trillion synapses (each storing about 5 bits), with a total storage capacity of about 1 petabyte, operating at extremely low sub-kHz frequencies—this "extremely slow but extremely large" strategy trades for full utilization of its massive internal storage. It's like a librarian who moves slowly but can work efficiently in a library containing 1 PB of books.
Neuroscience talks about how nature does things. The next question is: Where are AI systems currently stuck? Google engineer Xiaoyu Ma and Turing Award winner David Patterson (co-inventor of the RISC architecture and Google's chief engineer) will publish a paper in January 2026. From an engineering practice perspective, a conclusion highly consistent with neuroscience was reached (Patterson is also a chief engineer at Google, and his research aligns with Google's interests as the world's largest consumer of AI inference; readers should be aware of this background):
"The main challenge of LLM inference lies in memory and interconnects, not computation."
The key lies in a trend known as the "scissors gap": over the past 20 years, computing power has grown far faster than memory and networking. Server peak FLOPS have increased by 3.0 times every two years, but DRAM bandwidth has only increased by 1.6 times every two years, and interconnect bandwidth even slower, only 1.4 times every two years. Machines in factories are getting faster and faster, but trucks transporting raw materials have barely changed speed—the machines spend most of their time idling and waiting for goods.

Figure 1. "Scissors Gap": Over the past 20 years, computing power has increased by approximately 59,000 times, but DRAM bandwidth has only increased by about 110 times and interconnect bandwidth by only about 29 times. The difference is obvious on a logarithmic scale.
The situation is even worse from the cost perspective: For DRAM, the high-performance HBM (achieving extremely high bandwidth through TSV stacking), the type most needed for AI inference, is projected to see a 35% increase in unit cost from 2023 to 2025, while the cost of standard DDR memory is expected to decrease by about 50%. The more scarce the type of memory is in AI, the higher its price is rising. Multiple media outlets estimate OpenAI's inference costs to be in the billions of dollars annually—continuing to optimize FLOPS while neglecting memory/networking is no longer economically sustainable.
The third independent data point comes from the industry. Based on energy measurements from real-world data centers, IBM Research provides a straightforward figure:
"The majority of energy expenditure during AI runtime is spent on data transfer. Computational energy accounts for only about 10% of modern AI workloads." (Estimated by IBM Research scientist Hsinyu Tsai; the exact percentage varies significantly depending on workload type and configuration.)
The implication is clear: when you ask a question using ChatGPT, only about one-tenth of the power consumed by the GPU cluster is actually used for "thinking" (matrix multiplication), while the remaining 90% is spent on "data transfer"—reading model parameters from memory to computation units, writing intermediate results back to memory, and synchronizing states between different GPUs. The IBM NorthPole chip, with its near-memory computing architecture, validates the possibility of this "reverse direction"—in its target scenario (inference on a small model with 3 billion parameters), it is 47 times faster and 73 times more energy efficient than the most energy-efficient GPUs. It's important to note that the NorthPole architecture has not yet been validated on large models with tens of billions of parameters, but it demonstrates a principle: when data transfer bottlenecks are eliminated, energy efficiency can be improved by orders of magnitude.

Figure 2: Comparison of energy allocation between the human brain and AI systems. Both spend most of their energy on communication/data transfer, with computation accounting for only a small portion.
Three chains of evidence, from different perspectives, point to the same conclusion, but require precise articulation:
Under the current von Neumann architecture, the bottleneck and dominant energy consumption factor in AI systems (especially in the inference phase) is data movement (storage access + interconnect communication), rather than arithmetic computation itself. This bears a structural resemblance to the energy allocation pattern of the biological brain. The core challenge for future AI architectures is to narrow the "storage-computation" distance, rather than simply increasing computational speed.
This describes "where the bottleneck lies" rather than "what is unimportant"—computing power remains a necessary condition, but no longer a sufficient one.
From Training to Agent: Technological Requirements and Business Value at Four Stages
The three chains of evidence above clearly point in the right direction, but a natural question remains: how fast is this trend moving? Is it something for ten years from now, or is it already happening? To answer this question, we need to distinguish between the four stages of AI workloads—their hardware requirements and business logic are drastically different.
Stage 1: Training—Parallel computing, bandwidth is king.
Training is the most "compute-intensive" stage. Thousands of GPUs work simultaneously, with batch sizes reaching thousands or even tens of thousands—all training data is offline, no one waits for results, and a large batch of samples can be accumulated for computation together, resulting in extremely high GPU utilization. The communication mode is AllReduce—large blocks of data (MB to GB) synchronize gradients between GPUs, focusing on the bandwidth of the pipeline, not the speed at which the data runs (latency). NVLink has been optimized for training, increasing from 400Gbps to 800Gbps and then to 1.6Tbps.
Stage 2: Simple Inference/Chatbot—"Fast thinking," a single forward propagation.
When a user asks, "What's the weather like today?", the model performs a forward propagation, "reads" parameters, and outputs a few hundred tokens. This is similar to human "fast thinking"—answering intuitively without in-depth deduction. The requirements for computation and storage are low: short context (a few thousand tokens), small KV cache (a few GB), and released when the session ends.
Phase Three: Thinking (Inference Model)—"Slow Thinking," serial exploration, and a dramatic increase in memory and latency requirements.
Inference models like OpenAI o3 and DeepSeek R1 changed everything. They perform long internal "thinking" before answering—generating inference chains of thousands to tens of thousands of tokens, trying different paths, verifying intermediate results, and finally outputting the answer. This is similar to human "slow thinking"—repeatedly deducing on scratch paper when facing complex problems.
Hardware requirements have fundamentally changed. During training, the GPU is almost 100% busy (compute-bound), but the decoding phase of Thinking is naturally memory-bound—for each token generated, all the model weights must be read from HBM (70B model = 140GB), but the actual computation only takes a few milliseconds. Imagine the GPU as a factory with 10,000 workstations: during training, all are occupied, and the machines are running at full capacity; during inference, only 10 workers are working, and 9,990 are idle—time is spent moving raw materials (model weights) from the warehouse (memory) to the workstations.

Figure 3: Von Neumann bottleneck: During the inference of the 70B model, more than 90% of the time is spent waiting for data to be moved from memory, and computation accounts for less than 10%.
Meanwhile, Thinking reverses the communication mode from "bandwidth priority" to "latency priority." During training, the transfer of large data blocks (MB-GB) between GPUs results in a negligible 10-microsecond delay—it's negligible when spread across large data volumes. However, during Thinking's Decode phase, small data (KB-level) needs to be synchronized across GPUs for each token generated, at an extremely high frequency. Numerical verification: transferring 1KB of data at 400Gbps bandwidth takes 0.02 microseconds in pure transmission time, but network startup latency requires 5-10 microseconds. Latency accounts for 99.8% of communication waiting time.

Figure 4: Communication modes for three workloads. Training transmits large blocks of data (bandwidth is king), Thinking transmits small packets (latency is king), and the Agent alternates between the two without stopping.
Phase Four: Agent (Autonomous Execution) – The Highest Requirement, the Ultimate Challenge of the Memory Wall.
The Agent adds two dimensions to Thinking: continuous interaction with the external world (calling search engines, executing code, querying databases), and extremely long context maintenance (a coding agent may work continuously for hours without releasing the context).
The Agent's working mode is an alternating cycle of Prefill and Decode: each tool call returns a large chunk of results → a compute-intensive Prefill (parallel processing of new input) → then a long memory-bound Decode (serializing the next action) → another tool call → another Prefill… Each cycle further expands the KV Cache until it hits the memory limit. This means that compute and memory need to expand simultaneously – not simply "memory replacing compute," but the overall focus clearly shifts towards memory.

Figure 5: GPU utilization pattern of Agent workflow. Red tall bars (Prefill) and blue short bars (Decode) alternate, with the blue bars getting longer and longer—the memory-bound phase continues to expand.

Figure 6: The four stages of AI evolution. From Training to Agent, the hardware bottleneck has shifted from computing to storage and connectivity, while the commercial value has jumped from $20/month to $100,000+/year—high-value scenarios are precisely the most memory-bound.
The empirical study of 100 trillion tokens released by the OpenRouter platform in 2025 confirms the speed of this transformation: the token share of inference models surged from nearly zero at the beginning of 2025 to over 50%. Patterson's paper predicts that annual sales of inference hardware will grow 4-6 times over the next 5-8 years. Amin Vahdat, head of Google's AI infrastructure, has demanded that "inference service capacity be doubled every 6 months." The combined capex of the four major hyperscalers is expected to exceed $500 billion in 2026.
The simultaneous increase in technological demand and commercial value: Chatbots are "advanced search" costing $20/month, with limited user willingness to pay; however, the goal of agents is to replace human labor—the average white-collar worker in the US earns over $100,000 annually, and an agent capable of continuously performing complex tasks can capture hundreds of times more value than a chatbot. These highest-value scenarios are precisely those with the most demanding requirements for storage (TB-level KV cache) and latency (millisecond-level cross-GPU synchronization). The ceiling for AI commercialization is directly constrained by the physical limits of memory and interconnectivity.
The memory wall crisis in the era of agents
To understand the "memory wall" problem faced by Agent workloads, it's essential to understand a key concept: KV Cache.
LLM generates text by sequentially outputting tokens one by one, requiring each step to "see" information from all previous tokens. Transformers achieve this through an Attention mechanism—compiling a set of Key (index) and Value (content) vectors for each token. The current token determines which Values to reference by matching the Keys of all historical tokens. Without caching, each new token generation requires recalculating the K and V of all previous tokens—but these values remain unchanged, resulting in pure waste. KV Cache stores pre-calculated K/V vectors in GPU memory, avoiding redundant calculations. This is a significant performance optimization (reducing computation from O(n²) to O(n)), but at the cost of a larger cache and higher memory usage with longer contexts.
How large is the KV Cache? It depends on the model architecture. Mainstream models since 2024 have adopted GQA (Grouped Query Attention), replacing the traditional 64 KV headers with 8, directly reducing the KV Cache by a factor of 8. Calculated using the mainstream GQA 70B model:
上下文长度 | KV Cache | 硬件需求 | 对比:405B全MHA |
4K tokens(普通对话) | ~1.3 GB | H100很轻松 | ~10 GB |
32K tokens(长文档) | ~10 GB | H100绑绑有余 | ~80 GB |
128K tokens(Agent工作) | ~40 GB | 占H100一半内存 | ~1 TB |
1M tokens(长程Agent) | ~320 GB | 需要4张H100 | ~8 TB |

Figure 7: KV Cache grows linearly with context length (GQA 70B model, same scale).
A 40GB single-session KV cache seems manageable—but don't forget: the weights of the 70B model alone require 140GB (not even enough for a single H100 node). In actual deployments, the KV cache and weights compete for limited HBM space. Furthermore, 40GB represents only one user per session; an 8-GPU H100 node simultaneously serving 50 128K Agent sessions implies a 2TB KV cache—far exceeding the node's total HBM capacity of 640GB. The memory pressure in the Agent era isn't due to the size of individual KV caches, but rather the simultaneous existence and inability to release too many KV caches—unlike traditional chat sessions where caches are released upon completion, agents might work continuously for hours or even days.
This is the background to Patterson's HBF (High Bandwidth Flash) solution—adding a new storage tier between HBM and SSDs specifically for storing KV caches that require long-term persistence and high-bandwidth access.

Figure 8: Storage hierarchy pyramid for AI inference. Patterson's HBF fills a key gap between HBM and SSD—designed specifically for TB-level KV cache.
维度 | 传统推理 | Agent推理 |
上下文长度 | 4K-32K tokens | 128K-2M+ tokens |
会话持续时间 | 秒级 | 小时-天级 |
工具调用次数 | 0-3次 | 数十-数百次 |
KV Cache大小 | GB级 | 数十GB-TB级 |
状态持久化 | 不需要 | 必须跨会话保存 |
Token乘数 | 1-10x | 100-1000x |
The direct impact on the user experience. The limitation of the context window isn't just an abstract technical parameter—it directly affects the task complexity that the AI agent can handle. Anyone who has deeply used AI tools has experienced this problem: when tasks involve extensive searching, data validation, and repeated modifications, the conversation quickly approaches its context limit, forcing the system to trigger compaction—compressing early dialogue history into a summary to free up space. The result is that previously discussed data details, modification decisions, and validation conclusions are selectively "forgotten," requiring subsequent analysis to search and confirm them again. This isn't a problem with model intelligence, but rather a physical memory constraint—the context window is the "working memory" during inference, and its upper limit directly determines the task complexity and duration that the AI can handle. Every leap from the current practically usable level to the level of millions or tens of millions of tokens requires a proportional investment in HBM capacity and bandwidth.
If the memory cost of KV Cache (through HBM expansion, new HBF layers, or TurboQuant-like compression techniques) can be reduced by an order of magnitude, the context window can be expanded from the current 1M tokens to 10M or even 100M—then the AI Agent will no longer be limited to short tasks that "can be completed in a few hours," but can execute complex, multi-step tasks lasting several days, much like assigning work to a human employee: independently completing a full industry research report, managing a multi-cycle software development project, or continuously monitoring and optimizing an investment portfolio. The intermediate states, historical decisions, and trial-and-error experiences at each step are fully preserved in "working memory," without losing critical information due to compression. This is why memory is not just a hardware cost issue—it directly determines the scale of what AI can accomplish.
Faced with these challenges, the evolution direction of AI hardware is becoming clear: in-memory computing convergence (PIM/PNM/HBF) shortens data transport distances, quantization and sparsity reduce accuracy requirements, MoE enables sparse activation, and low-latency network fabric replaces bandwidth-first topologies. These four directions are highly similar to the architecture that biological brains have "chosen" over hundreds of millions of years of evolution: brain synapses are both storage and computing units (in-memory computing fusion), operate with extremely low precision (1-8 bit equivalent), only about 15% of neurons are active at the same time (sparse activation), and adopt a small-world network topology (low latency priority).

Figure 9: Brain architecture and AI hardware are converging toward the same future through four paths (in-memory computing fusion, quantization/sparseness, MoE, and low-latency networks).
Efficiency improvement, supply and demand pattern and cycle positioning
The preceding text academically argued for the structural trend of "storage + connectivity dominance." However, for investment, correct direction does not equate to correct timing—three questions still need to be answered: Will efficiency improvements erode demand? Will there be oversupply? Where are we currently in the cycle?
TurboQuant and the Efficiency Paradox
On March 25, 2026, Google Research released TurboQuant—an algorithm that compresses the KV cache from 16-bit to 3-bit, reducing memory usage by 6 times, increasing inference speed by up to 8 times, and claiming zero precision loss. SK Hynix fell 6.2% in a single day, Samsung fell 4.7%, and Micron fell 7%. The market logic is straightforward: if the memory required for inference suddenly decreases by 6 times, shouldn't the supercycle end?
The market reacted quickly, but the logic doesn't stand up to scrutiny. First, TurboQuant isn't exactly new—its core component QJL and PolarQuant's arXiv preprints were published in June 2024 and February 2025 respectively, circulating in academia for nearly a year; Google merely gave it a high-profile product launch. Second, it has only been validated on small 7-8B models like Gemma and Mistral; its performance on cutting-edge 70B+ models is unknown. Third, Google hasn't released any official code, so integration into mainstream inference frameworks (vLLM, Ollam) is unlikely before Q3-Q4. Finally, and most fundamentally: it only compresses the KV cache, not the model weights (the 140GB of parameters for 70B models remains unaffected), doesn't affect training, and doesn't touch on interconnect latency—the two core pillars argued in this paper are completely unaffected.
However, what's truly worth pondering isn't TurboQuant's technical limitations, but a more fundamental economic principle: the Jevons Paradox. The 19th-century economist Jevons discovered that the increased efficiency of steam engines didn't reduce coal consumption—in fact, because steam engines became more economical and practical, coal demand skyrocketed. LEDs are 10 times more energy efficient than incandescent bulbs, yet global electricity consumption for lighting has actually increased. Twelve months ago, DeepSeek demonstrated the possibility of training powerful models with fewer resources, leading to a panic sell-off of NVIDIA shares—but subsequently, total demand for AI inference exploded, pushing NVIDIA to record highs.
If TurboQuant is widely adopted, the same logic will unfold: a 6x compression of the key-value cache means the same GPU memory can support 6 times longer contexts, or more than 6 times the number of concurrent agents, or make scenarios previously impossible due to memory limitations feasible—the increase in total demand is likely to exceed the savings per unit of demand. Google's own actions validate this: while releasing TurboQuant, it announced a capex of $175-185 billion (doubling) by 2026, with the head of AI infrastructure demanding "doubling inference capacity every six months." The very existence of TurboQuant confirms our argument—memory is a critical bottleneck, which is why it's worthwhile for a Google Fellow and their team to spend two years tackling it.
Price and Supply & Demand: Where is the Cycle?
A more pragmatic question than TurboQuant's: Has DRAM price peaked?
The spot price of 16GB DRAM (D5) peaked on March 19, 2026, before falling back, with the contract premium narrowing from 30% to approximately 20%. Superficially, this seems like a bearish signal. Our judgment is that it's a correction, not a cyclical reversal—DRAM profits in this cycle are likely to follow a "wide-top plateau" pattern, rather than the sharp drop typical of past cycles. This is because the supply-side response is significantly lagging compared to previous cycles.
In past memory cycles, as soon as prices rose, the three major manufacturers frantically expanded production, leading to oversupply and a price collapse 6-12 months later. But this cycle is different. Total DRAM capex is projected to grow from $53.7 billion to $61.3 billion in 2026 (+14% YoY), but the investment focus is not on building new production lines: SK Hynix's M15X is used for HBM3e and HBM4, Micron's $20 billion is used for 1-gamma node conversion and TSV equipment, and Samsung's $20 billion is mainly for 1C process HBM. The portion that can actually translate into DRAM bit output growth is extremely limited—the industry bit output growth rate in 2026 is only about 10-15% (mainly from the increased output per wafer due to the die shrink from 1β/1C to 1-gamma, rather than new wafer inputs), while demand growth is over 20%. Even considering the implicit capacity expansion effect of process upgrades, the supply-demand gap is still widening.
The "capacity siphon effect" of HBM exacerbates this problem: 1GB of HBM consumes about 3-4 times the wafer area of standard DRAM (HBM3e requires 8 layers of TSV stacking). By 2026, AI high-speed memory will consume nearly 20% of the world's total DRAM production capacity (in terms of equivalent area). After this 20% is "absorbed", the supply of standard DDR5 will be severely squeezed, creating a "double shortage" that has never occurred in previous cycles.
The timeline for bringing new production capacity into operation is also much longer than the market expected:
项目 | 预计投产 | 满产 |
Micron Boise (Idaho) | 2027年中 | 2028+ |
Micron 广岛HBM厂 | 2028 | 2029+ |
SK Hynix M15X(主要用于HBM4) | 2026 Q4 | 2027+ |
SK Hynix 龙仁集群 | 2029+ | 2030+ |
Samsung P5 | 2027年底 | 2028+ |
Samsung Taylor (Texas) | 2027年初 | 2028+ |
There is virtually no new capacity added in 2026. It's not that manufacturers don't want to expand, but rather that capacity is being siphoned off by HBM (Hypermobile Manufacturing Systems), new plant construction takes 2-3 years, and the painful lessons of 2022-2023 have significantly tightened the capital discipline of the three major manufacturers. SK Hynix's internal analysis predicts that the DRAM supply shortage will continue at least until the end of 2028.
The demand structure is also reinforcing this assessment. In the past, memory cycles were driven by PCs and mobile phones—highly cyclical and dominated by consumer sentiment. However, the core incremental growth in this round comes from AI infrastructure: hyperscalers are locking in volume with 3-5 year LTA contracts, Google Cloud has a backlog of $240 billion in orders, and the four major hyperscalers' combined capex in 2026 will exceed $500 billion. These are already contracted, rigid demands, not speculative expectations.
DRAM is ultimately a cyclical industry; a "wide top" does not equal a "perpetual high." However, meaningful supply easing is expected no earlier than mid-2027 to 2028. The bottom of this cycle has been structurally raised—even if a correction occurs in the future, the decline is unlikely to be as deep as the drops in 2019 or 2022.
Investment Implications and Industry Chain Mapping
That concludes the technical analysis. For investors, there's only one question: Where is the money going? How is this structure changing?
Based on Bedrock's tracking model, the following is an estimate of the evolution of the AI server capex structure from 2025 to its long-term endgame (~2038):
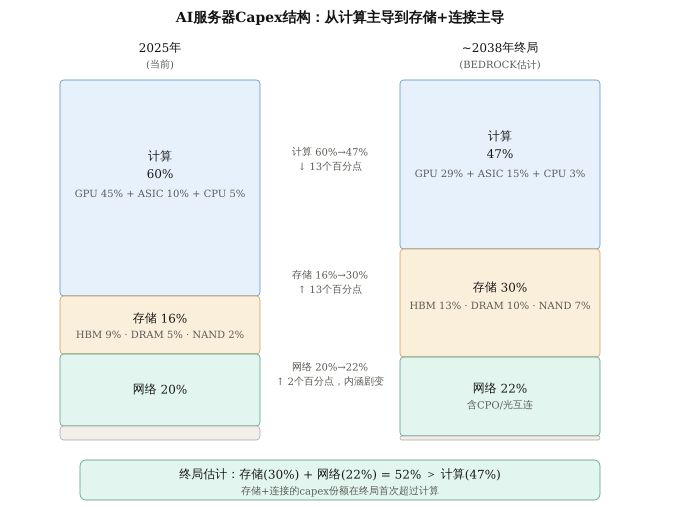
Figure 10. Evolution of AI server Capex structure from 2025 to the end of 2038 (BEDROCK estimate). Storage + connectivity combined increases from 36% to 52%, surpassing computing (47%) for the first time. Note: GPU refers to the value of the pure chip/accelerator card, excluding HBM (HBM is included in storage). The end-of-year figure for 2038 is a directional estimate, and the specific proportions are subject to significant uncertainty.
Key takeaways:
Computing (GPU + ASIC + CPU) share drops from 60% to 47%, a dramatic shift in internal structure. GPU share decreases from 45% to 29%, ASIC share rises from 10% to 15% (due to the rise of custom inference chips like Google TPU and AWS Trainium), and CPU share decreases from 5% to 3% (ARM CPU integration like Grace reduces independent costs, but the serial orchestration requirements of the Agent era ensure CPUs won't disappear). Custom inference chips like Google TPU, AWS Trainium, and Meta MTIA have risen in the Agent era. For NVIDIA, NVLink/NVSwitch interconnects are a unique ecosystem barrier; even with the decline in GPU share, the interconnect value may continue.
Storage share rises from 16% to 30%—but the path isn't linear. Between 2026 and 2028, due to a surge in DRAM/HBM prices, storage share will briefly spike to 45-47%, then fall back and stabilize at 29-31% as new capacity comes online and prices normalize. This endgame level is far below the peak, but still nearly double what it was before 2025—the memory intensity of the Agent era is structural and won't return to its original level with price cycles. NAND rose from 2% to 7%, reflecting the rise of Patterson's HBF layer in AI inference.
Network increased from 20% to 22%, shifting completely from "bandwidth-first" to "latency-first." The 20% in 2025 is primarily driven by InfiniBand/NVLink and pluggable optical modules. The 22% in 2038 will consist of CPO (co-packaged optoelectronics), high-radix low-latency switches, and flattened network topologies optimized for inference/Agents. The technology stack is almost entirely replaced. Investment opportunities are not "more similar devices," but "completely different new technologies"—the CPO supply chain, high-radix switching chips, and silicon photonics foundry.
The most important figure: Storage (30%) + Networking (22%) = 52%, surpassing Computing (47%) for the first time. From 36% vs 60% in 2025 to 52% vs 47% in 2038—the market share has almost reversed. The value focus of AI infrastructure is shifting from "who has the fastest GPU" to "who has the deepest storage and the lowest interconnect latency."
Based on this evolution of the capex structure, value is shifting towards the following areas:
HBM/DRAM (SK Hynix, Samsung, Micron) is rising from a "supporting role" in AI infrastructure to a constraining bottleneck. Goldman Sachs predicted in March 2026 that SK Hynix's traditional DRAM prices would increase by 243% year-on-year, with capacity sold out by the end of 2026. HBM4 is entering mass production. Looking further ahead, if HBF mass production is successful, it will open up a completely new storage tier—specifically for terabyte-level KV cache.
The importance of high-speed interconnects/optical modules (Lumentum, Coherent, Broadcom, Marvell) is clearly pointed out in Patterson's paper. CPO transformation and continued growth in demand for 800G/1.6T optical modules are driving this trend.
Advanced packaging (TSMC CoWoS, ASE, BESI) is the physical foundation for achieving "closer proximity" between memory and computing. HBM's 3D stacking and Logic-on-Memory architecture all rely on advanced packaging.
NVIDIA has clearly recognized this trend. NVIDIA is actively transforming from a pure GPU chip manufacturer into a system-level solutions provider. The GB200 NVL72 is a landmark product of this transformation—it's not just a chip, but a rack-mount AI computer integrating 72 GPUs, 36 Grace CPUs, a 13.5TB unified HBM3e memory pool, 130TB/s NVLink interconnect, and a liquid cooling system. It costs $2-3 million, weighs 1.36 tons, and consumes 120kW. NVIDIA is no longer just selling GPU dies—it's selling complete systems including GPUs, CPUs, memory, interconnect, cooling, and software. The next-generation Vera Rubin platform goes a step further: the NVL144 configuration connects 144 GPUs into a single 8 exaflops computing domain. On the software side, the CUDA ecosystem, the NeMo framework, and the DGX Cloud service have created a 5-7 year customer lock-in effect. This means that even if the share of GPUs in capex drops from 45% to 29%, NVIDIA's actual total capex share, achieved through upstream expansion (Grace CPU) and downstream expansion (NVLink interconnect, system integration, and software platform), may be far higher than 29%—it has a presence in computing, networking, and even cooling.
Key Uncertainties
HBF (High Bandwidth Flash) mass production timeline. Can NAND write endurance and read latency be engineered and resolved in AI inference scenarios?
In-memory computing technology roadmap. Should computing power be directly integrated into the memory chip (PIM, Processing-in-Memory, such as Samsung HBM-PIM), or should the computing chip be placed next to the memory (PNM, Processing-near-Memory)? Both routes are underway, and which one reaches commercial scale first will impact the competitive landscape of memory suppliers.
Model architecture innovation. Large-scale adoption of MoE may alleviate memory-bound issues; successful neural recurrence could improve token efficiency by 1000 times—these could all change the perception of "storage + connectivity dominance."
Geopolitics. HBM is concentrated in South Korea (SK Hynix, Samsung), while advanced packaging is concentrated in Taiwan (TSMC CoWoS).
In summary,
"The future of AI will be driven by storage and connectivity"—this is largely true. Computing power remains a necessary condition, but no longer a sufficient one. When GPU computing power is excessive while storage bandwidth and interconnect latency cannot keep up, adding more GPUs is futile.
This judgment holds even more true in the Agent/inference era than in the training era. As AI evolves from training → inference → Agent, the workload shifts from compute-bound to memory-bound, and the importance of "storage + connectivity" is systematically increasing.
Three independent chains of evidence—neuroscience (brain communication consumes 35 times more energy than computation), computer architecture (Patterson points out that the bottleneck of LLM inference lies in memory and interconnects), and industrial testing (IBM estimates that computation accounts for only about 10% of AI's energy consumption)—point to the same direction from different starting points. BEDROCK's capex structure analysis quantifies this trend into a specific number: by the end of 2038 (directional estimate), storage (30%) + network (22%) = 52%, surpassing computation (47%) for the first time—a near reversal from 36:60 in 2025.
Limitations of the analysis: The brain analogy is insightful but not equivalent (difference in precision between analog and digital computation); Patterson, as Google's chief engineer, has research aligned with Google's business interests; the capex end-game prediction (~2038) has a large margin of error; the adoption rate of efficiency technologies like TurboQuant may exceed expectations; the biggest risk of the "wide-top" hypothesis lies on the demand side—if AI commercialization progresses slower than expected, the hyperscaler's capex may suddenly tighten.
1.Levy, W.B. & Calvert, V.G. (2021). "Communication consumes 35 times more energy than computation in the human cortex." PNAS, 118(18).
2.Balasubramanian, V. (2021). "Brain power." PNAS, 118(32).
3.Ma, X. & Patterson, D. (2026). "Challenges and Research Directions for LLM Inference Hardware." arXiv:2601.05047.
4.IBM Research (2025). "How the von Neumann bottleneck is impeding AI computing."
5.OpenRouter (2026). "State of AI: An Empirical 100 Trillion Token Study."
6.TrendForce (2025). "Memory Industry to Maintain Cautious CapEx in 2026, with Limited Impact on Bit Supply Growth."
7.TrendForce (2025). "AI Reportedly to Consume 20% of Global DRAM Wafer Capacity in 2026."
8.Goldman Sachs (2026). "Goldman Sachs Raises Samsung Targets as Memory Boom Reshapes Chip Industry." 2026年3月.
9.Zandieh, A. et al. (2025). "TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate." ICLR 2026.
10.Google Research (2026). "TurboQuant: Redefining AI Efficiency with Extreme Compression."
11.Cannell, J. "Brain Efficiency: Much More than You Wanted to Know." LessWrong.
12.Semiengineering (2026). "AI Workloads Are Turning The Data Center Network Into A Combined Memory And Storage Fabric."
13.WEKA (2025). "What Is the AI Memory Wall and Why Is It an Existential Threat to Inference Performance?"
14.CNBC (2025). "Google Must Double AI Serving Capacity Every 6 Months to Meet Demand."
15.Micron Q1 FY2026 Earnings Call (2025). "Micron Technology Q1 FY 2026 Sets Records."



Comments