
When the fast world of AI collides with the slow world of reality
- BedRock

- May 11
- 18 min read
We are still very optimistic about the capability curve of AI: models are getting stronger, tasks are longer, and AI R&D itself is beginning to be automated. The real question is how quickly the real world can pick it up, embed capabilities into workflows, and ultimately translate into revenue or cost improvements.
May 5, 2026 · BEDROCK AI memo
By 2026, AI will have no shortage of grand narratives and capital expenditures. BofA has drawn the CY27 capex path of hyperscaler to $1Tn; Google Cloud backlog has reached $460B+; Microsoft AI business annualized revenue has exceeded $37B. The question is no longer “will AI continue to invest?”, but whether the real world can turn these investments into real productivity.
Recently we had a chat with BY (pseudonym), a front-line AI engineer. He has been on the front line of AI productization for a long time. What he talks about most is not the model list, but what will happen when coding agents, enterprise AI and physical AI are actually implemented. Comparing this with Anthropic co-founder and Import AI author Jack Clark’s collection of public data on AI R&D automation, and BEDROCK’s continuous tracking of capex, backlog, memory, optical, and semicap, we see two sides of the same thing. BEDROCK's core judgment is that the barriers to AI are moving from "how smart the model is" to "how the model is incorporated into real work."
On the one hand, there is the fast world of AI: the capability curve continues to steepen, AI research and development itself begins to be automated, and the task span may continue to lengthen. The other side is the real slow world: after capabilities enter the real organization, they will encounter workflow, feedback, data, acceptance and responsibility chains. What we really care about is the intersection of the two: capabilities continue to grow, but productivity doesn’t happen automatically.
IAI’s fast world: the ability curve is indeed steep
Let’s start with the model layer. How far is the difference between OpenAI's Codex and Anthropic's Claude Code? On the surface, it is a comparison of two products, but behind it is a bigger question: how long can the model layer form a barrier.
BY's judgment is very straightforward: "There is no difference of one year in this era. According to Musk's rhythm, it is only two months; more pragmatically speaking, it is about four months." The point of this sentence is not to be accurate to a few months, but that the time unit has changed. The model layer is still important, but it is difficult to rely on a generation difference of one or two years to form a long-term barrier.
Jack Clark gave a more intuitive set of data in Import AI 455: SWE-Bench went from 2% at the end of 2023 to 93.9% in mid-2026; AI R&D tasks such as CORE-Bench are also rising rapidly. Looking at a single benchmark may be noisy, but multiple tasks are penetrated together, indicating that cutting-edge capabilities continue to improve, and the diffusion of open capabilities is getting faster and faster.
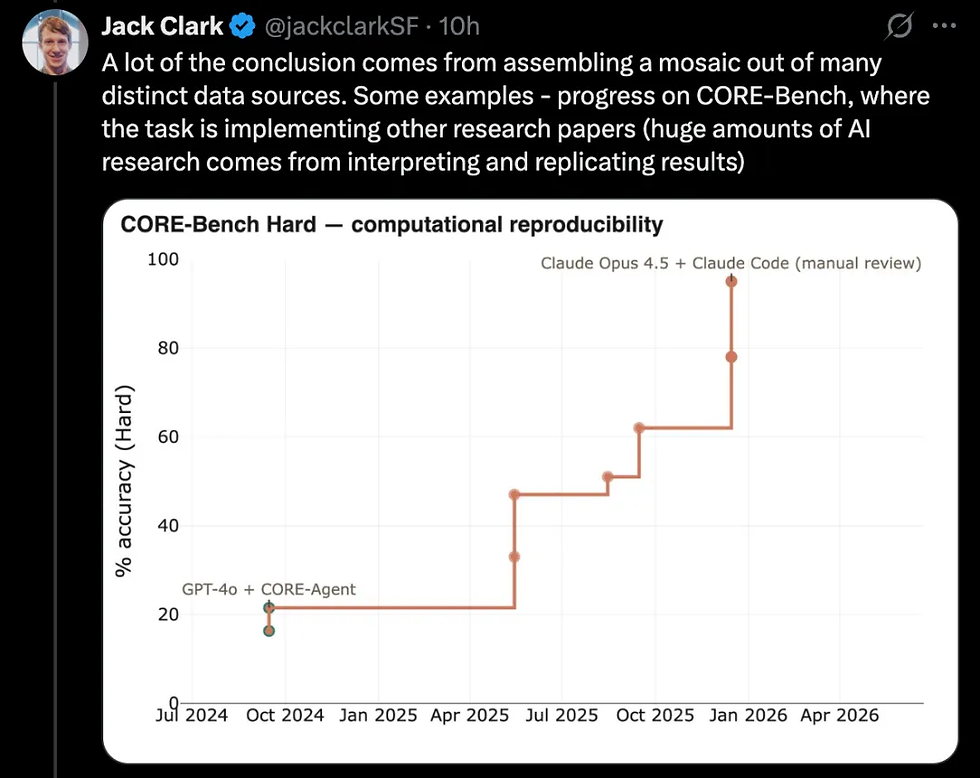
Original picture by Jack Clark: AI research and development tasks such as CORE-Bench are also on the rise rapidly. The focus is not on a certain benchmark, but that the diffusion of model capabilities is happening across multiple tasks. This is the strongest evidence in the fast world: model capabilities are not only improving in chatting, writing code, and solving problems, but are also beginning to enter AI research and development itself. Reproducing experiments, optimizing training codes, and running benchmarks all provide shorter feedback. Once the agent can participate stably, the capability curve may continue to steepen.
This is not to say that model companies have no value. Where leaders really spend their time is often not the final score, but a lot of trial and error in the front: how to wash data, how to run the agent loop, how to connect tools, how to recover from failures, and how to accept user acceptance. When the recipe is understood by the industry, latecomers will be able to pursue the model faster; but the experience that actually enters the workflow will not be copied equally quickly.
The fast world is more than just model scores. More importantly, the agent is changing the work cycle itself: people are no longer stuck in the loop at every step, and the machine starts running the loop on its own. In other words, AI begins to push work from human speed to machine speed.
IIAgent: People change from executors to managers
The biggest difference between Agent and chatbot is not that the answers are longer, but that people are no longer stuck in each loop. In the Copilot/Chat era, people have to constantly prompt, read, and prompt again; in the agent era, people define goals, and the agent breaks down tasks, calls tools, checks results, and finally reaches an acceptable result.

Coatue: From Copilot/Chat to Agent, the key change is that human required in every loop becomes human becomes the manager. The good thing about this picture is that it does not describe agent as a smarter chat box, but as a change in the way labor is organized. The so-called labor is no longer human-limited does not mean that people are no longer important, but that the human bottleneck has shifted from execution to management: defining goals, setting boundaries, and accepting results. The figures from "1 analyst helping you" to "1,000 analysts working 24/7" are certainly exaggerated, but they are in the right direction: work is no longer completely controlled by a person's typing speed and check-in frequency.
Because of this, changes in the agent will fall on two accounts at the same time: one is the productivity account, and the other is the infrastructure account. The work cycle changes from human speed to machine speed, and tokens, contexts, tests, and tool calls will all be amplified. A representative detail: Anthropic’s compute tension is now tighter than a year ago, not looser.
The reason is not just that there are more users. The token consumption model itself has changed:
In the past, tokens were for people to see - the faster you typed, the faster the model was generated, but you couldn't see it anyway.
Now the token is for the agent - the agent is relentless and can run forever.
This sentence explains a lot of things. When a coding agent performs real tasks, it will continuously read files (tens of thousands of lines of code for a medium-sized project are hundreds of thousands of tokens), write code, run tests, fix errors, summarize, and read the context again. It is not uncommon for complex tasks to consume millions of tokens; in the chat era, a conversation usually only has a few thousand to tens of thousands of tokens. Therefore, the $200/month subscription is actually a subsidy for heavy agent users, and the real reasoning cost may be several times or even ten times higher. On the other side, long-running agents require memory, context, scheduling, and tool invocation, and the load will also spread from the GPU to memory, CPU, storage, and network.
Therefore, what is more intuitive is not the "number of users", but the token curve. Coatue estimates that the annual token value of OpenAI + Anthropic + Gemini API will be almost flat in 2023, reaching about 16.4K trillion by the end of 2025, and will continue to rise in 2026. The focus here is not to be precise at every point, but the slope: the agent pushes the call frequency from human speed to machine speed.

Coatue: API token consumption has gone from human chat speed to a steeper slope driven by agent workflows. This also explains why capex continues to increase. The CY27 hyperscaler capex path given in the BofA report at the end of April is $1Tn, and CY26 is already $700B+; Google's 1Q26 financial report disclosed that Cloud backlog has nearly doubled to $460B+, Direct API Gemini token 16B/minute, quarter-on-quarter +60%; Microsoft AI sales annualized $37B+, year-on-year +123%. The logic behind it is not complicated: the agent is relentless, it continues to swallow tokens, and the tokens will eventually fall to the hardware requirements.
Looking at the load structure again: inference is becoming heavier than training. Two years ago, the industry estimated that training accounted for 70-80% of AI compute and inference 20-30%; now the load of many hyperscalers has been reversed. This structural change is particularly meaningful for the storage chain: training requires HBM, inference also requires HBM, but NAND/eSSD is needed to store KV cache, model checkpoint, and user context. Citi said in its April report that NAND CY26 ASP increased by 172% year-on-year and SSD segment increased by 242%. This is not like ordinary cyclical fluctuations, but more like the storage TCO reconstruction in the agent era.
We prefer to think of this round of capex as an expansion of the “reasoning factory”. Agent turns inference into a continuously running workload. The data center will continue to evolve from a "training cluster" to a comprehensive system of "training + inference + storage + network". GPU/ASIC will still be the core, but the bottleneck will spread to HBM, NAND/eSSD, data center networking, optical communications, EDA and test simultaneously. In the training era, the main thing to buy is peak computing power; in the agent era, you also need to buy context, caching, scheduling, reliability and low latency. In other words, capex is not simply buying more cards, but redoing the entire infrastructure for longer tasks, higher concurrency, and lower error rates.
The next step in the fast world is to move tasks upward. The model moves from doing questions and completing codes to longer and more complete work; but the higher the task, the slower the feedback will be.
III tasks moved up: from E4 to E5
Coding agent It is easiest to observe "model ability" and "work ability" separately. Meta engineer level is a good reference.
If we look at Meta's engineer level, E3 is a newcomer, E4 can deliver features independently, E5 can take an independent project and push it forward, and E6 starts to define the direction and lead several E5s. The level systems of Google and Amazon have different names, but the meanings are similar. "The current level of coding agents, I think, is a very high level of L4 - strong E4," BY said, "but there is still a long way to go before jumping to E5."
From E4 to E5, there is not an intelligence gap. A more accurate analogy is that of a smart person entering the workplace from school:
You imagine a top MIT graduate - the intelligence is already there, he has never worked in the workplace. Training him into Facebook E5 does not rely on further intelligence improvement, but on environment, instruction, and long-term feedback.
From E4 to E5, what is lacking is not IQ but workplace training. E5 must be able to proactively judge what to do, remember project history, understand business constraints, be responsible for results, and have a taste developed from a large amount of feedback. None of these can be directly measured by benchmark scores.

AI is already strong at E4, but what is needed to jump to E5 is not smarter, but deeper "workplace training." The difficulty is that the feedback cycle of project-level work is too long. Whether a feature is written correctly can be verified in a few minutes; whether a project is in the right direction may take several months. The model will also "compress" requirements during long tasks, compressing 100 requirements into the top 20 key points, and slowly discarding the subsequent details. A longer context window helps, but it is no substitute for the real work environment.
From E4 to E5, you can’t just wait for the model to be “smarter”. It requires external memory, task tracking, document rules, skill library, and verification checklist, which is the harness mentioned above. Whoever builds this working environment first will be more likely to define the next generation of coding agents.
Jack Clark takes the problem even further. He judged in Import AI 455 that if multiple benchmarks in AI R&D continue to advance simultaneously, recursive self-improvement may become a real scenario around 2028. The probability of 60% can be discounted, but the question is already very specific: How quickly does the span of tasks that AI can work on independently become longer?

Jack Clark’s public judgment on the AI R&D timeline for AI automation. We do not take this as a conclusion, but once E5/project-level capabilities are commercialized, the subsequent schedule may be significantly moved forward. The task duration indicator of METR (Model Evaluation & Threat Research) is more direct: when the AI system reaches 50% reliability on a set of tasks, the "skilled human completion time" corresponding to these tasks.

METR data: AI missions spanned from 30 seconds to 12 hours in just 4 years. If the trend continues, it could be 100 hours (~two weeks of continuous work) by the end of 2026, which is exactly the time scale for E5 / real project-level work. If this curve continues, BY said "there is still a distance from E4 to E5", it may not be 3-5 years, but 12-18 months. Ajeya Cotra (METR researcher) believes that it is not an outrageous assumption that AI systems will complete "100 hours of human work" by the end of 2026. 100 hours is roughly the time scale from requirement to MVP after an E5 engineer gets an independent project. The explosion of Cursor, Devin, and Codex CLI in the past six months is to productize the ability to "work independently for several hours"; when the task length changes from hours to days to weeks, the product form will change again.
Model companies and cloud vendors continue to increase their investment, betting on a jump in task span. As long as task spans really push from "hours" to "days and weeks," AI is no longer just a chatbot subscription, but is entering the labor replacement and augmentation market for software development, data analysis, customer service, internal operations, and even R&D. Today, many inference costs seem expensive, but capital is still willing to endure it because it is betting on the value behind it: when AI can stably complete project-level work, both ARPU and the serviceable market may be repriced.

Aggressive scenario from Joseph Jacks/OSS Capital: Anthropic ARR hits $2T by 2030. BEDROCK does not regard it as a base case, but such figures represent the market’s imagination of the “AI workforce platform”. We do not consider this $2T ARR path as a base case. It puts Anthropic's run-rate ARR and Alphabet's GAAP revenue in the same picture, which itself needs to be discounted; there are also many constraints in between, from computing power supply, corporate procurement rhythm, gross margin to competitive landscape. But when the market discusses this kind of numbers, it looks at the entrance to “automatable work” rather than selling more chatbots. Cloud vendors' capex today looks like an arms race, and they are essentially buying this option.
IV feedback loop determines redemption order
After the task span becomes longer, the next level of question is: Which type of work can be converted into productivity first? The answer is usually not the “biggest” task, but the task with the shortest feedback. What really determines where AI becomes productive first is the feedback loop.
The feedback loop of coding is naturally short. After writing the code for the model, you can immediately compile, test, run, view diff, and read the error log. You will know where you went wrong within a few minutes and then fix it. The "hypothesis-verification" cycle can be closed within the machine, and there is no need to wait for users, the market, or the boss.
The shorter the feedback, the easier it is for AI to improve and be commercialized.
Many enterprise scenarios are slow not because the models are not smart enough, but because there is no such clear and dense feedback. The feedback cycles for product, strategy, and organizational management are weekly, monthly, and quarterly. There is a lot of noise, and attribution is difficult.
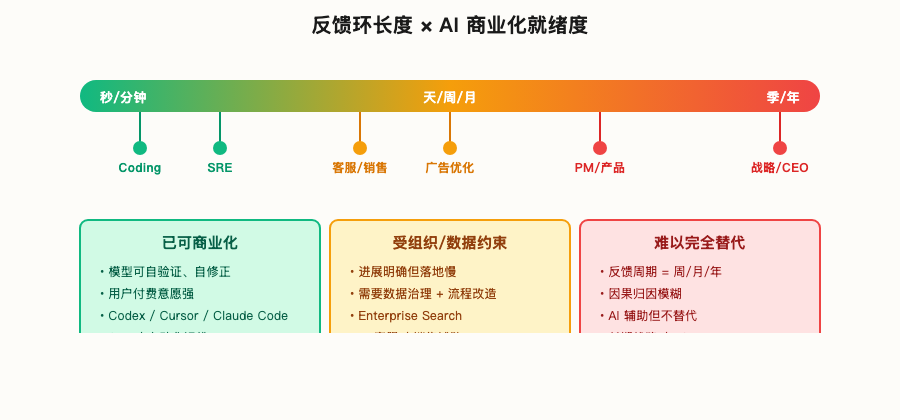
The shorter the feedback loop, the sooner AI can enter operational verification and put it into the business scenario. The workflow of the short feedback loop will come out first: customer support work order, SRE on-call, code review, contract template filling, and insurance claim preliminary review. Jobs where feedback is very long - market strategy, organizational design, long-term decision-making - AI can assist, but it is still far from being a complete replacement.
AI R&D itself may be one of the workflows with the shortest feedback loop. If AI can participate in training code optimization, experiment replication, benchmark improvement, and model fine-tuning, the feedback it will receive is not the organizational results in a few years, but the loss, speedup, and score in minutes or hours.
Clark listed a very specific example in Import AI 455: Anthropic internally allows AI to optimize CPU-only small language model training implementation. In the past year, AI has accelerated from 2.9x to 52x; human researchers usually need 4-8 hours to achieve 4x for similar tasks. This is not yet "AI will make itself AI", but the shortest feedback loop will be the first to accelerate itself.
If this path continues, model iteration, harness deployment, and computing power requirements will all be compressed schedules. AI research and development itself may enter self-acceleration first, and capex needs to be read in a different way: not only the training requirements, but also the agent inference requirements.
The second half: the real slow world
At this point, it is already clear in the fast world: models are getting stronger, agents are mechanizing work cycles, and AI research and development itself may also accelerate itself. The real disagreement is not whether AI will continue to improve, but whether the real world can catch up with these advances.
V Slow World: The same model, why is the effect so different?
After entering a real organization, the question is no longer just whether the model is smart enough, but what supports this set of capabilities. Jack is talking about the capability slope; we want to know more about what will become barriers when this slope hits the real workflow. Therefore, at the company level, we will pay more attention to harness. This word is difficult to translate in Chinese, and it would be awkward to translate it hard. In fact, it can be simply understood as: when the model enters the work site, there is a complete set of tools, rules and acceptance mechanisms outside.
The simplest difference is: you open the same model separately and let it answer "Help me change this code", which is one effect; putting it into a real repo so that it can read files, run tests, retain plans, retry after failure, and finally return key judgments to others is another effect. The former is model ability, while the latter is closer to work ability.
AI productivity does not "grow" by the model itself, but is layered layer by layer. The bottom layer is the model; the upper layer is the harness, which determines whether the model can work stably; the higher layer is the scene data, which determines whether it knows how to do things "here"; the top layer is the organizational process, which determines whether the things it produces can be adopted, accepted, and entered into P&L. The higher you go, the closer it is to the real ROI and the less likely it is to be copied.
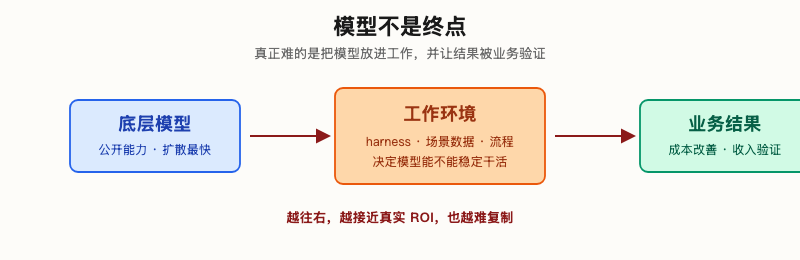
The model is just the starting point; the real hard part is putting it into a working environment and getting the results into the business. This is something that is not new to the history of software. Cloud computing does not rely on a single VM to retain customers, but relies on storage, databases, permissions, monitoring, billing and operation and maintenance processes to be tied together. It is not the SQL syntax itself that is difficult to migrate, but the cost of migration becomes high after the business system, data model, reports and permissions are incorporated.
AI also has this structure. The real stickiness is not "which model is used", but "what environment the model is installed into". Coding style, business rules, permission system, data governance and acceptance standards determine whether the model can produce stable output. Just connecting to an external API without its own harness and scene data will easily lose its value in the end.
Growth in VI capabilities does not equal growth in income
Looking at BEDROCK's "fast world/slow world" framework, AI is a fast world inside, and real organizations are a slow world. Model capabilities can be iterated on a weekly or monthly basis, but customer acceptance, budget approval, data governance, organizational processes, and user habits often change on a quarterly or even yearly basis.
Doubling internal capabilities does not mean doubling external income. If the outside world cannot catch up, capabilities will first be stuck in acceptance, process, and budget.
Coding is closer to the fast world of AI, and feedback can be verified by machine. Enterprise AI, advertising revenue, and Physical AI have to move through the real, slow world. There is a layer of real friction between the growth of AI capabilities and revenue growth.

Capacity improvement occurs in the fast world of AI, while income verification is often stuck in the real slow world. VIIMeta: Productivity comes first to the cost side
The fast world of AI and the slow world of reality are easiest to see clearly in Meta. If AI doubles Meta engineer productivity, will Meta’s revenue also double?
The key is: "Meta's improved model capabilities in AI are not bottlenecked by productivity. It is bottlenecked by experiments that can run." Translated into business language: Meta's bottleneck is not how many codes engineers can write, but how many real A/B experiments it can run in a year.
Where is the Meta card? First, the overall budget of the advertiser is stuck - the market is only so big, and it won't suddenly become more popular just because the model becomes smarter. It's also stuck in the user's attention - everyone only has 24 hours a day, and AI can't change it.
More critical is the experimental capacity. A/B testing requires real traffic, a minimum crowd size, and sufficient time; although Meta's total traffic is large, it is divided by thousands of experiments by hundreds of teams. The "experimental share" that can truly be allocated to a new function is limited. Further back, there are product experience thresholds, privacy regulation, antitrust litigation and TikTok competition.
At Meta, the impact of AI will first be reflected on the cost side. The same people can run more projects, OpEx benefits, and profit margins expand first. To affect the revenue side, AI needs to really create new product forms, new advertising inventory, and new willingness to pay—and these are all things in the slow world, and the cycle may be several years. This is also consistent with Meta’s disclosures in the past few quarters: capex continues to increase ($125-145B in 2026), revenue growth remains high in single digits to +15%, and what AI is really doing is bringing operational efficiency to a higher level, rather than making the revenue curve suddenly steeper.
VIII Enterprise AI: Workflow is the starting point
In addition to hardware, what the enterprise really needs to change is workflow. Many companies narrowed the question at first: instead of "buying a GPT to connect to the API and let it do X for me", they changed the workflow from "human-led" to "AI execution + human acceptance". At the end of the day, budget will ultimately go to workflow refactoring, not API wrappers.
This is not about buying software, but about changing the organization. The company needs to reorganize the process, identify links that can be taken over or accelerated by AI, establish its own skill library, prompt templates, knowledge base and tool calling rules, hand over repetitive work to agents, and then design acceptance mechanisms and human oversight. The Manager's responsibilities will also change: from managing people to managing goals, systems, and acceptance.
This will differentiate two types of companies. The first type is like consulting and delivery: helping customers sort out processes, connect systems, and make customizations. Income can increase, but each project is very heavy. The second type is more like a platform: abstracting the workflow, data schema, permission rules and acceptance mechanisms accumulated in deployments into reusable products. The latter is closer to the long-term form of “installing AI into organizations”.
Palantir is a prime example. It does not necessarily have the strongest model, but it has customer relationships, data systems, compliance systems and private deployment capabilities. The most difficult thing in scenarios such as government, military industry, and energy is not to connect an API, but to let AI enter existing systems, permissions, and responsibility chains. Whoever can accomplish this is closer to real productivity.
The further away from the software feedback loop, the more intermediate constraints there are, and the less directly extrapolated AI can be to productivity. Physical AI is the most typical example: model capability is only one layer, and the real difficulty is system integration.
IXPhysical AI: Slow in system integration
One step further into Slow World is Physical AI. In this area, judgment needs to be more restrained: companies such as Optimus and Figure are making rapid progress, but ready intelligence (LLM brain) does not mean system ready.
So the question is not “Is the body ready?”, but: What is the body is ready?
Body is ready is a false proposition. Even if the brain is strong enough and the body is good enough, if the integration is not good, the performance will be poor.
Robotaxi is a better analogy to understand. Compared with humanoid robots, its task boundaries are actually narrower: the car only needs to drive on the road, and does not need to open doors, pick up things, or climb stairs. But security, long-tail scenarios, supervision and public trust have firmly dragged it into the slow world. At Tesla Autonomy Day in 2019, Musk said that there will be millions of Tesla robotaxi vehicles in 2020; in reality today, the advancement of robotaxi is still a matter of liberalizing cities, regions, weather, and regulations. The gap here cannot be explained by "the model is not smart enough".
A perfect visual model plus a perfect car does not equal autonomous driving. The key is the end-to-end integration of sensor, control, decision, and safety. The same is true for robots: perception, control, action planning, feedback delay, software and hardware collaboration, if any one of them is missing, it will be useless no matter how smart the brain is.
This is the “Moravec Paradox” that has characterized robotics for decades—computers can easily do things that humans find difficult (playing chess, solving calculus), but things that humans find easy (picking up an egg, walking across an uneven surface) are extremely difficult for robots.
It has been 27 years since Boston Dynamics was founded in 1992 to launch its first commercial product, Spot, in 2019; Stretch will be commercialized in 2022. This is not because the team is not strong enough, but because the complexity of the physical world inherently takes so long. Although the recent demos of new-generation companies such as Physical Intelligence, Figure, and 1X look amazing, there is still a long way to go from the demo to being able to run stably for 1,000 hours in a customer factory.
This is not bearish on physical AI. Once integration is broken through, progress will suddenly accelerate; but it has not yet reached the stage of verifiable commercialization. Unlike coding, robots must solve body, perception, control, safety and scene data at the same time, and feedback is also very slow. It's going to be a big opportunity, but it's not going to end with just putting the LLM brain on it.
Finally, back to BEDROCK’s main judgment: the focus of AI analysis must shift upward. In the past two years, it has been easy for us to chase benchmarks; but after the fast world of AI collides with the slow world of reality, we should ask three things: how short the feedback loop is, how deep the stack is, and whether the organization can absorb it. Model scores will be tied, but harness, scenario data, organizational processes, and customer relationships will not be tied so quickly.
Therefore, we don’t really want to worry about “which day is the AGI moment”. In fact, few technologies in human history have simultaneously reshaped model capabilities, software development, capital expenditures, and organizational processes at the speed of today’s AI. If by singularity we mean that capability curves are steepened, feedback loops are shortened, and production methods are reorganized, then it is not some future date but a state of affairs that we are already in.
No singulation, all singularity.
In fact, we don’t need to wait for a singularity moment, because we are already there.



Comments