
AI架构深度研究:存储与连接的时代?
- BedRock

- 3月31日
- 讀畢需時 16 分鐘
从神经科学到Capex结构:AI硬件价值链正在重构
01AI的未来应以存储和连接为主导?
02从Training到Agent:四阶段演进
03Agent时代的内存墙与KV Cache
04效率提升、供需格局与周期定位
05投资含义与产业链映射
06总结
AI的未来应以存储和连接为主导,计算占比只是小部分?
神经科学家研究大脑、计算机架构师研究芯片、工程师测量数据中心——三个完全不同领域的研究者,从各自的起点出发,却不约而同地指向了同一个结论:AI系统的瓶颈和主要能量消耗在于数据移动(存储访问+互连通信),而非算术计算本身。
弗吉尼亚大学William B. Levy和Victoria G. Calvert在《美国国家科学院院刊》(PNAS)发表了一篇论文,标题直截了当:《Communication consumes 35 times more energy than computation in the human cortex(人类皮层中通信消耗的能量是计算的35倍)》。
要理解这项研究,首先需要理解他们对"计算"和"通信"的定义。在大脑中,"计算"指的是单个神经元根据其接收到的突触输入信号,对局部环境变量做出推断和预测——类似于一个微型传感器在分析它接收到的数据。"通信"则是将这些推断结果从一个神经元传送到另一个神经元的过程——包括动作电位沿轴突传导(信号在电线中传播)、突触囊泡释放神经递质(在两根电线之间传递化学信号)、以及事后回收离子恢复电位差(给电池重新充电)。
人脑总功耗约17W(基于PET扫描数据,修正了此前常引用的20W粗略估算)。扣除散热损耗(8.89W)后,仅有约4.94 ATP-W可用于实际脑功能。其中分配给皮层计算的能量仅约0.1W——通信消耗的能量是计算的35倍。
Balasubramanian在PNAS的配套评论中总结:大脑演化的核心优化目标并非最大化计算速度,而是在严格的能量约束下,优化通信效率以支撑分布式计算。大脑拥有约200万亿个突触(每个存储约5 bits),总存储容量约1 petabyte,以极低的亚kHz频率运行——这种"极慢但极大"的策略,换取了对其巨量内部存储的充分利用。就像一个图书馆管理员走得很慢,但能在一座藏有1PB书籍的图书馆中高效工作。
神经科学说的是大自然怎么做的。下一个问题是:AI系统目前卡在哪?Google工程师Xiaoyu Ma与图灵奖得主David Patterson(RISC架构联合发明人、Google首席工程师)在2026年1月发表论文。从工程实践角度,得出了与神经科学高度一致的结论(Patterson同时是Google首席工程师,其研究方向与Google作为全球最大AI推理消费者的利益一致,读者应了解这一立场背景):
"LLM inference的主要挑战在于内存和互连,而非计算。"
关键在于一个被称为"剪刀差"的趋势:过去20年,计算能力的增长速度远远快于内存和网络。服务器峰值FLOPS以每2年增长3.0倍的速率提升,但DRAM带宽仅每2年1.6倍,互连带宽更慢,仅每2年1.4倍。工厂里的机器越来越快,但原材料运输的卡车速度几乎没变——机器大部分时间在空转等货。

图1 · "剪刀差":20年来计算能力累积增长约59,000倍,但DRAM带宽仅约110倍、互连仅约29倍。对数坐标下差距一目了然。
从成本端看更糟糕:同样是DRAM,AI推理最需要的高性能品种HBM(通过TSV堆叠实现极高带宽)从2023到2025年单位成本上涨35%,而普通的标准DDR内存反而下降约50%。越是AI稀缺的那种内存,越在涨价。OpenAI的推理成本据多家媒体估算在每年数十亿美元量级——继续优化FLOPS而忽视内存/网络,在经济上已不可持续。
第三个独立的数据点来自产业界。IBM Research基于实际数据中心的能量测量,给出了一个直接的数字:
"AI运行时的主要能量支出花在数据传输上。计算能量仅占现代AI工作负载的约10%。"(IBM Research科学家Hsinyu Tsai的估计值,具体比例因工作负载类型和配置有显著差异)
含义很直接:当你用ChatGPT问一个问题时,GPU集群消耗的电力中,只有约十分之一真正用于"思考"(矩阵乘法运算),剩下的九成花在了"搬运数据"上——把模型参数从内存读到计算单元,把中间结果写回内存,在不同GPU之间同步状态。IBM NorthPole芯片通过近存计算架构验证了"反方向"的可能性——在其目标场景(30亿参数的小型模型推理)中比最节能GPU快47倍、能效高73倍。需要注意的是,NorthPole的架构尚未在百亿参数级大模型上验证,但它证明了一个原理:当数据搬运瓶颈被消除后,能效可以提升多个数量级。

图2 · 人脑与AI系统的能量分配对比。两者都把大部分能量花在通信/数据搬运上,计算仅占一小部分。
三条证据链从不同角度指向了同一结论,但需要精确表述:
在当前冯·诺依曼架构下,AI系统(特别是推理阶段)的瓶颈和能量消耗主导因素是数据移动(存储访问+互连通信),而非算术计算本身。这与生物大脑的能量分配模式存在结构性相似。未来AI架构的核心挑战是缩小"存储-计算"距离,而非单纯提升计算速度。
这描述的是"瓶颈在哪"而非"什么不重要"——算力仍是必要条件,但不再是充分条件。
从Training到Agent:四个阶段的技术需求与商业价值
上面三条证据链的方向很清楚,但一个自然的追问是:这个趋势有多快?是十年后的事,还是正在发生?要回答这个问题,需要区分AI工作负载的四个阶段——它们的硬件需求和商业逻辑截然不同。
阶段一:Training(训练)—— 并行计算,带宽为王。
训练是最"compute-intensive"的阶段。数千张GPU同时工作,batch size可达数千甚至上万——所有训练数据是离线的,没人等结果,可以攒一大批样本一起算,GPU利用率极高。通信模式是AllReduce——大块数据(MB到GB级)在GPU之间同步梯度,关心的是管道有多粗(带宽),而不是数据跑多快(延迟)。NVLink从400Gbps堆到800Gbps再到1.6Tbps,就是为训练优化的。
阶段二:Simple Inference(简单推理/Chatbot)—— "快思考",一次前向传播。
用户问一句"今天天气怎么样",模型做一次前向传播,从参数中"读数",输出几百个token。类似于人的"快思考"——凭直觉回答,不需要深入推演。对计算和存储的要求都不高:上下文短(几千token),KV Cache很小(几GB),会话结束就释放。
阶段三:Thinking(推理模型)—— "慢思考",串行探索,内存和延迟需求剧增。
OpenAI o3、DeepSeek R1等推理模型改变了一切。它们在回答之前会进行长长的内部"思考"——生成数千到数万token的推理链,尝试不同路径,验证中间结果,最终才输出答案。这类似于人的"慢思考"——面对复杂问题时在草稿纸上反复推演。
硬件需求发生了根本性转变。训练时GPU几乎100%忙碌(compute-bound),但Thinking的Decode阶段天然是memory-bound的——每生成一个token,都要把模型全部权重从HBM读一遍(70B模型=140GB),但实际计算只需要几毫秒。把GPU想象成一个有10,000个工位的工厂:训练时全坐满,机器满负荷运转;推理时只有10个工人在工作,9,990个空着——时间花在从仓库(内存)搬运原材料(模型权重)到工位上。

图3 · 冯·诺依曼瓶颈:70B模型推理时,90%以上时间在等内存搬运数据,计算只占不到10%。
同时,Thinking将通信模式从"带宽优先"翻转为"延迟优先"。训练时GPU间传MB-GB级大数据块,延迟多10微秒无所谓——摊到大数据量上可忽略。但Thinking的Decode阶段每生成一个token都要跨GPU同步小数据(KB级),频率极高。数字验证:传1KB数据,400Gbps带宽下纯传输时间=0.02微秒,但网络启动延迟需要5-10微秒。延迟占通信等待的99.8%。

图4 · 三种工作负载的通信模式。Training传大块数据(带宽为王),Thinking传小包裹(延迟为王),Agent两者交替且永不停歇。
阶段四:Agent(自主执行)—— 最高要求,内存墙的终极挑战。
Agent在Thinking的基础上增加了两个维度:与外部世界的持续交互(调用搜索引擎、执行代码、查询数据库),以及极长的上下文维持(一个coding agent可能连续工作数小时,上下文从未释放)。
Agent的工作模式是Prefill和Decode的交替循环:每次工具调用返回大块结果→先做一次compute-intensive的Prefill(并行处理新输入)→然后进入漫长的memory-bound Decode(串行生成下一步行动)→再调用工具→再Prefill……每一轮循环都让KV Cache进一步膨胀,直到撞上内存上限。这意味着compute和memory需要同时扩张——不是简单的"memory取代compute",但整体重心明确向memory倾斜。

图5 · Agent工作流的GPU利用率模式。红色高柱(Prefill)和蓝色矮条(Decode)交替出现,蓝色越来越长——memory-bound阶段持续扩大。

图6 · AI四阶段演进。从Training到Agent,硬件瓶颈从计算转向存储+连接,同时商业价值从$20/月跃升到$10万+/年——高价值场景恰好是最memory-bound的。
OpenRouter平台2025年发布的100万亿token实证研究印证了这一转变的速度:推理模型的token占比从2025年初接近零飙升至超过50%。Patterson论文预测inference硬件年销售额未来5-8年将增长4-6倍。Google AI基础设施负责人Amin Vahdat要求"每6个月将推理服务容量翻倍"。四大hyperscaler 2026年合计capex预计超过$500B。
技术需求和商业价值的同步递增:chatbot是$20/月的"高级搜索",用户付费意愿有限;但Agent的目标是替代人类劳动力——美国普通白领的年薪在$10万以上,一个能持续执行复杂任务的Agent的value capture可以比chatbot高出数百倍。而这些最高价值的场景,恰恰是对存储(TB级KV Cache)和延迟(毫秒级跨GPU同步)要求最苛刻的场景。AI商业化的天花板,直接受制于内存和互连的物理极限。
Agent时代的内存墙危机
要理解Agent工作负载面临的"内存墙"问题,需要先理解一个关键概念:KV Cache。
LLM生成文本是逐个token串行输出的,每一步都需要"看到"前面所有token的信息。Transformer通过Attention机制实现这一点——为每个token计算一组Key(索引)和Value(内容)向量,当前token通过与所有历史token的Key匹配来决定参考哪些Value。如果不做缓存,每生成一个新token都要把前面所有token的K和V重算一遍——但这些值不会变,纯属浪费。KV Cache就是把已算好的K/V向量存在GPU内存里,避免重复计算。这是一个巨大的性能优化(计算量从O(n²)降到O(n)),但代价是:上下文越长,缓存越大,内存占用越高。
KV Cache有多大?取决于模型架构。2024年后的主流模型都采用了GQA(Grouped Query Attention),用8个KV头替代传统的64个,KV Cache直接缩小8倍。以主流的GQA 70B模型计算:
上下文长度 | KV Cache | 硬件需求 | 对比:405B全MHA |
4K tokens(普通对话) | ~1.3 GB | H100很轻松 | ~10 GB |
32K tokens(长文档) | ~10 GB | H100绑绑有余 | ~80 GB |
128K tokens(Agent工作) | ~40 GB | 占H100一半内存 | ~1 TB |
1M tokens(长程Agent) | ~320 GB | 需要4张H100 | ~8 TB |

图7 · KV Cache随上下文长度线性增长(GQA 70B模型,同比例尺)。
40GB的单会话KV Cache看起来可控——但别忘了:70B模型的权重本身就要140GB(一张H100都放不下),实际部署中KV Cache和权重要争抢有限的HBM空间;而且40GB只是一个用户一个会话,一台8卡H100节点同时服务50个128K Agent会话意味着2 TB的KV Cache——远超节点的640GB总HBM容量。Agent时代的内存压力不是因为单个KV Cache太大,而是太多KV Cache同时存在、且不能释放——传统聊天会话结束就释放,Agent可能连续工作数小时甚至数天。
这就是Patterson提出HBF(High Bandwidth Flash)方案的背景——在HBM和SSD之间增加一个新存储层级,专门存放需要长期保持但又要求高带宽访问的KV Cache。

图8 · AI推理的存储层级金字塔。Patterson提出的HBF填补了HBM与SSD之间的关键空白——专为TB级KV Cache设计。
维度 | 传统推理 | Agent推理 |
上下文长度 | 4K-32K tokens | 128K-2M+ tokens |
会话持续时间 | 秒级 | 小时-天级 |
工具调用次数 | 0-3次 | 数十-数百次 |
KV Cache大小 | GB级 | 数十GB-TB级 |
状态持久化 | 不需要 | 必须跨会话保存 |
Token乘数 | 1-10x | 100-1000x |
用户端的直接体验。Context window的限制不是抽象的技术参数——它直接影响AI Agent能完成的任务复杂度。任何深度使用过AI工具的人都体验过这个问题:当任务涉及大量搜索、数据验证、反复修改时,会话很快接近context上限,系统不得不触发compaction(上下文压缩)——将早期对话历史压缩为摘要以腾出空间。结果是:之前讨论过的数据细节、修改决策、验证结论被选择性"遗忘",后续分析不得不重新搜索和确认。这不是模型智能的问题,而是物理性的内存约束——context window就是推理时的"工作记忆",它的上限直接决定了AI能够承担的任务复杂度和持续时间。从当前的实际可用水平到百万、千万token级别的每一步跨越,背后都需要成比例的HBM容量和带宽投入。
如果KV Cache的内存成本(通过HBM扩容、HBF新层级、或TurboQuant类压缩技术)能够下降一个数量级,context window可以从当前的1M tokens扩展到10M甚至100M——那么AI Agent就不再局限于当前这种"几小时内完成"的短任务,而是可以像给一个人类员工布置工作一样,执行持续数天的复杂多步骤任务:独立完成一份完整的行业研究报告、管理一个多周期的软件开发项目、或者持续监控和优化一个投资组合。每一步的中间状态、历史决策、试错经验都完整保留在"工作记忆"中,不会因为压缩而丢失关键信息。这就是为什么内存不只是一个硬件成本问题——它直接决定了AI能做多大的事情。
面对这些挑战,AI硬件的演进方向正在变得清晰:存算融合(PIM/PNM/HBF)缩短数据搬运距离、量化和稀疏化降低精度需求、MoE实现稀疏激活、低延迟网络fabric替代带宽优先的拓扑。这四个方向恰好与生物大脑在数亿年演化中"选择"的架构高度趋同——大脑的突触同时是存储和计算单元(存算融合)、以极低精度运行(1-8 bit等效)、仅约15%的神经元同时活跃(稀疏激活)、采用小世界网络拓扑(低延迟优先)。

图9 · 大脑架构与AI硬件通过四条路径(存算融合、量化/稀疏化、MoE、低延迟网络)正在向同一个未来收敛。
效率提升、供需格局与周期定位
前文从学术层面论证了"存储+连接主导"的结构性趋势。但对投资而言,方向正确不等于时机正确——还需要回答三个问题:效率提升会不会侵蚀需求?供给端会不会过剩?当前处于周期的哪个位置?
TurboQuant与效率悖论
2026年3月25日,Google Research发布了TurboQuant——一个将KV Cache从16-bit压缩到3 bit的算法,内存占用缩小6倍,推理速度提升最高8倍,声称零精度损失。SK Hynix单日-6.2%,三星-4.7%,美光-7%。市场的逻辑很直接:如果推理需要的内存突然少了6倍,超级周期是不是该结束了?
市场反应快,但逻辑经不起推敲。首先,TurboQuant并不算新——其核心组件QJL和PolarQuant的arXiv预印本分别发表于2024年6月和2025年2月,在学术界流通了近一年,Google只是做了一次高调的产品化宣传。其次,它只在Gemma、Mistral等7-8B小模型上验证过,70B+前沿模型上的效果未知。再次,Google没有发布任何官方代码,进入主流推理框架(vLLM、Ollama)最快也要Q3-Q4。最后也是最根本的:它只压缩KV Cache,不压缩模型权重(70B模型的140GB参数不受影响),不影响训练,不触及互连延迟——本文论证的两大核心支柱完全不受影响。
但真正值得深思的不是TurboQuant的技术局限,而是一个更根本的经济学规律:Jevons悖论。19世纪经济学家Jevons发现,蒸汽机效率提升并未减少煤炭消耗——反而因为蒸汽机变得更经济实用,煤炭需求暴增。LED能效是白炽灯10倍,全球照明用电不降反升。12个月前DeepSeek展示了用更少资源训练强模型的可能性,NVIDIA被恐慌抛售——随后AI推理总需求反而爆发式增长,NVIDIA创历史新高。
TurboQuant如果广泛采用,同样的逻辑会展开:KV Cache压缩6倍意味着同样的GPU内存可以支撑6倍长的上下文、或6倍多的并发Agent、或让此前因内存限制而无法部署的场景变得可行——总需求的增长很可能超过单位需求的节省。Google自身的行为也验证了这一点:一边发布TurboQuant,一边宣布2026年capex高达$175-185B(翻倍),AI基础设施负责人要求"每6个月将推理容量翻倍"。TurboQuant的存在本身恰恰确认了我们的论点——内存正是因为是关键瓶颈,才值得Google Fellow带团队花两年去攻克。
价格与供需:周期在哪里?
一个比TurboQuant更务实的问题是:DRAM价格是否已经见顶?
D5 16G现货价格在2026年3月19日触及高点后回落,合约价溢价从30%收窄至约20%。从表面看这像是利空信号。我们的判断是修正而非周期反转——DRAM利润这一轮大概率走一个"宽顶平台"形态,而非过去周期中典型的尖顶急跌。原因在于供给端的响应比以往周期显著滞后。
过去的内存周期中,价格一涨,三家厂商就拼命扩产,6-12个月后供应过剩、价格崩塌。但这一轮不同。2026年DRAM总capex预计从$53.7B增长到$61.3B(+14% YoY),投资重心却不是建新产线:SK Hynix的M15X用于HBM3e和HBM4,Micron的$20B用于1-gamma节点转换和TSV设备,三星的$20B以1C工艺HBM为主。真正能转化为DRAM bit output增长的部分极为有限——2026年行业bit output增速仅约10-15%(主要来自1β/1C到1-gamma的die shrink带来的每晶圆产出提升,而非新增晶圆投入),而需求增速在20%以上。即使计入工艺升级的隐性扩产效应,供需缺口仍在扩大。
HBM的"产能虹吸效应"加剧了这个问题:1GB HBM消耗约3-4倍标准DRAM的晶圆面积(HBM3e需要8层TSV堆叠)。到2026年AI高速内存将消耗全球DRAM总产能的近20%(等效面积计)。这20%被"吸走"后,标准DDR5的供给被严重挤压——形成过去周期中从未出现过的"双重紧缺"。
新产能的投产时间线也远比市场想象的长:
项目 | 预计投产 | 满产 |
Micron Boise (Idaho) | 2027年中 | 2028+ |
Micron 广岛HBM厂 | 2028 | 2029+ |
SK Hynix M15X(主要用于HBM4) | 2026 Q4 | 2027+ |
SK Hynix 龙仁集群 | 2029+ | 2030+ |
Samsung P5 | 2027年底 | 2028+ |
Samsung Taylor (Texas) | 2027年初 | 2028+ |
2026年几乎没有实质性新增产能。不是厂商不想扩,而是产能被HBM虹吸、新厂建设需要2-3年、2022-2023年的惨痛教训让三家厂商的资本纪律显著收紧。SK Hynix内部分析预测DRAM供不应求至少持续到2028年底。
需求端的结构也在加固这个判断。过去内存周期由PC和手机驱动——高度周期性、消费者情绪主导。但本轮核心增量来自AI基础设施:hyperscaler用3-5年LTA合约锁量,Google云积压订单$240B,四大hyperscaler 2026年合计capex超$500B。这些是已签约的刚性需求,不是投机性预期。
DRAM终究是周期性行业,"宽顶"不等于"永远的高点"。但有意义的供给缓解最早在2027年中至2028年。本轮周期的底部被结构性抬高——即使未来出现调整,跌幅也不太可能重演2019年或2022年的深度下跌。
投资含义与产业链映射
技术分析到此为止。对投资而言只有一个问题:钱花在哪里?这个结构在怎么变?
基于BEDROCK的跟踪模型,以下是AI服务器capex结构从2025年到长期终局(~2038年)的演变估计:
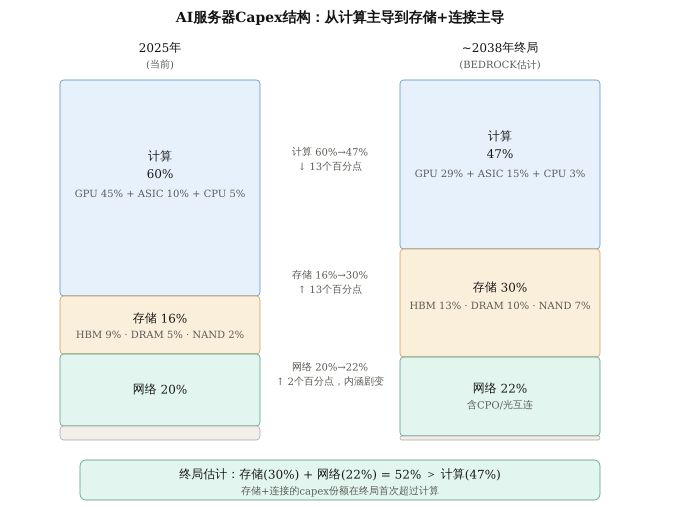
图10 · AI服务器Capex结构从2025年到~2038年终局的演变(BEDROCK估计)。存储+连接合计从36%升至52%,首次超过计算(47%)。注:GPU指纯芯片/加速卡价值,不含HBM(HBM计入存储)。2038年终局为方向性估算,具体比例存在较大不确定性。
几个关键读法:
计算(GPU+ASIC+CPU)份额从60%降至47%,内部结构剧变。GPU从45%降至29%,ASIC从10%升至15%(Google TPU、AWS Trainium等定制推理芯片崛起),CPU从5%降至3%(Grace等ARM CPU集成降低独立开支,但Agent时代串行编排需求使CPU不会消失)。Google TPU、AWS Trainium、Meta MTIA等定制推理芯片在Agent时代崛起。对NVIDIA来说,NVLink/NVSwitch互连是独有的生态壁垒,即使GPU份额下降,互连价值可能持续。
存储从16%升至30%——但路径不是直线上升。2026-2028年因DRAM/HBM价格暴涨,存储占比会短暂冲高至45-47%,随后随新产能投产和价格正常化,回落并稳定在29-31%。这个终局水平远低于峰值,但仍比2025年前高出近一倍——Agent时代的memory-intensity是结构性的,不会随价格周期回到原点。其中NAND从2%升至7%,反映了Patterson提出的HBF层级在AI推理中的崛起。
网络从20%升至22%,内涵从"带宽优先"彻底转向"延迟优先"。2025年的20%主要是InfiniBand/NVLink和可插拔光模块。2038年的22%则由CPO(光电共封装)、高radix低延迟交换机、以及为推理/Agent优化的扁平化网络拓扑构成。技术栈几乎完全替换。投资机会不是"更多的同类设备",而是"完全不同的新技术"——CPO供应链、高radix交换芯片、硅光子代工。
最重要的数字:存储(30%) +网络(22%) = 52%,首次超过计算(47%)。从2025年的36% vs 60%到2038年的52% vs 47%——份额几乎对调。AI基础设施的价值重心从"谁的GPU最快"转向"谁的存储最深、互连延迟最低"。
基于这个capex结构演变,价值正在向以下环节转移:
HBM/DRAM(SK Hynix, Samsung, Micron)从AI基础设施的"配角"升格为约束性瓶颈。Goldman Sachs 2026年3月预测SK Hynix的传统DRAM价格同比涨幅达243%,产能售罄至2026年底。HBM4进入量产。更长远看,HBF如果量产成功,将开辟全新的存储层级——专门容纳TB级KV Cache。
高速互连/光模块(Lumentum, Coherent, Broadcom, Marvell)的重要性被Patterson论文明确指出。CPO转型、800G/1.6T光模块需求持续增长。
先进封装(TSMC CoWoS, ASE, BESI)是实现"存算靠近"的物理基础。HBM的3D堆叠、Logic-on-Memory架构全部依赖先进封装。
NVIDIA显然也看到了这个趋势。NVIDIA正在积极地从纯粹的GPU芯片厂商转型为系统级解决方案提供商。GB200 NVL72就是这个转型的标志性产品——它不是一颗芯片,而是一个集成了72颗GPU、36颗Grace CPU、13.5TB统一HBM3e内存池、130TB/s NVLink互连、液冷系统于一体的整机柜级AI计算机,售价$2-3M,重1.36吨,功耗120kW。NVIDIA不再只卖GPU die——它卖的是GPU+CPU+内存+互连+冷却+软件的完整系统。下一代Vera Rubin平台更进一步:NVL144配置将144颗GPU连成一个8 exaflops的单一计算域。在软件端,CUDA生态、NeMo框架、DGX Cloud服务形成了5-7年的客户锁定效应。这意味着即使GPU在capex中的份额从45%降至29%,NVIDIA通过向上游(Grace CPU)、向下游(NVLink互连、系统集成、软件平台)扩张,实际能够捕获的总capex份额可能远高于29%——它在计算、网络、甚至冷却环节都有布局。
关键不确定性
HBF(High Bandwidth Flash,高带宽闪存)量产时间线。NAND的写入寿命和读取延迟是否能在AI推理场景中被工程化解决?
存算融合的技术路线。把计算能力直接集成到内存芯片内部(PIM, Processing-in-Memory,如Samsung HBM-PIM),还是把计算芯片放在内存旁边(PNM, Processing-near-Memory)?两条路线都在推进,谁先到商用规模将影响内存供应商的竞争格局。
模型架构革新。MoE大规模普及可能缓解memory-bound;neuralese recurrence若成功,token效率可能提升1000倍——这些都可能改变"存储+连接主导"的判断。
地缘政治。HBM集中在韩国(SK Hynix, Samsung),先进封装集中在台湾(TSMC CoWoS)。
总结
"AI未来以存储和连接为主导"——基本成立。算力仍是必要条件,但不再是充分条件。当GPU算力过剩而存储带宽和互连延迟跟不上时,增加更多GPU无济于事。
这一判断在Agent/推理时代比训练时代更加成立。随着AI从训练→推理→Agent演进,工作负载从compute-bound转向memory-bound,"存储+连接"的重要性权重在系统性上升。
三条独立的证据链——神经科学(大脑通信能耗是计算的35倍)、计算机架构(Patterson指出LLM推理瓶颈在内存和互连)、工业实测(IBM估计计算仅占AI能耗约10%)——从不同起点指向了同一个方向。而BEDROCK的capex结构分析将这个方向量化为一个具体的数字:到~2038年终局(方向性估算),存储(30%) + 网络(22%) = 52%,首次超过计算(47%)——从2025年的36:60几乎对调。
分析的局限性:大脑类比有启发性但不能等同(模拟计算vs数字计算的精度差异);Patterson作为Google首席工程师,研究方向与Google商业利益一致;capex终局预测(~2038年)误差范围很大;TurboQuant类效率技术的采用速度可能超预期;"宽顶"假说的最大风险在需求端——如果AI商业化进展慢于预期,hyperscaler的capex可能突然收紧。
1.Levy, W.B. & Calvert, V.G. (2021). "Communication consumes 35 times more energy than computation in the human cortex." PNAS, 118(18).
2.Balasubramanian, V. (2021). "Brain power." PNAS, 118(32).
3.Ma, X. & Patterson, D. (2026). "Challenges and Research Directions for LLM Inference Hardware." arXiv:2601.05047.
4.IBM Research (2025). "How the von Neumann bottleneck is impeding AI computing."
5.OpenRouter (2026). "State of AI: An Empirical 100 Trillion Token Study."
6.TrendForce (2025). "Memory Industry to Maintain Cautious CapEx in 2026, with Limited Impact on Bit Supply Growth."
7.TrendForce (2025). "AI Reportedly to Consume 20% of Global DRAM Wafer Capacity in 2026."
8.Goldman Sachs (2026). "Goldman Sachs Raises Samsung Targets as Memory Boom Reshapes Chip Industry." 2026年3月.
9.Zandieh, A. et al. (2025). "TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate." ICLR 2026.
10.Google Research (2026). "TurboQuant: Redefining AI Efficiency with Extreme Compression."
11.Cannell, J. "Brain Efficiency: Much More than You Wanted to Know." LessWrong.
12.Semiengineering (2026). "AI Workloads Are Turning The Data Center Network Into A Combined Memory And Storage Fabric."
13.WEKA (2025). "What Is the AI Memory Wall and Why Is It an Existential Threat to Inference Performance?"
14.CNBC (2025). "Google Must Double AI Serving Capacity Every 6 Months to Meet Demand."
15.Micron Q1 FY2026 Earnings Call (2025). "Micron Technology Q1 FY 2026 Sets Records."



留言