
当AI的快世界,撞上现实的慢世界
- BedRock

- 5月11日
- 讀畢需時 13 分鐘

2026 年 5 月 5 日 · BEDROCK AI memo
到 2026 年,AI 已经不缺宏大叙事,也不缺资本开支。BofA 把 hyperscaler 的 CY27 capex 路径画到 $1Tn;Google Cloud backlog 已到 $460B+;Microsoft AI 业务年化收入过 $37B。问题已经不是“AI 会不会继续投入”,而是现实世界能不能把这些投入变成真实生产力。
最近我们和一线 AI 工程师 BY(化名)聊了一次。他长期在 AI 产品化一线,谈到最多的不是模型榜单,而是 coding agent、企业 AI 和 physical AI 真正落地时会遇到什么。再对照 Anthropic 联合创始人、Import AI 作者 Jack Clark 对 AI 研发自动化的公开数据整理,以及 BEDROCK 对 capex、backlog、memory、optical、semicap 的持续跟踪,看到的是同一件事的两面。BEDROCK 的核心判断是:AI 的壁垒正在从“模型有多聪明”,上移到“模型被怎样装进真实工作”。
一面是 AI 的快世界:能力曲线继续变陡,AI 研发本身开始被自动化,任务跨度可能继续拉长。另一面是现实的慢世界:能力进入真实组织之后,会撞上工作流、反馈、数据、验收和责任链。我们真正关心的是两者的交汇处:能力继续变强,但生产力不会自动发生。
AI 的快世界:能力曲线确实很陡
先从模型层说起。OpenAI 的 Codex 和 Anthropic 的 Claude Code,到底差多久?表面是两个产品的比较,背后是一个更大的问题:模型层还能形成多久的壁垒。
BY 的判断很直接:“现在这个时代没有差一年的。按马斯克的节奏,也就两个月;务实一点说,大概四个月。”这句话的重点不是精确到几个月,而是时间单位变了。模型层仍然重要,但很难再靠一两年的代差形成长期壁垒。
Jack Clark 在 Import AI 455 里给过一组更直观的数据:SWE-Bench 从 2023 年底的 2%,走到 2026 年中的 93.9%;CORE-Bench 这类 AI 研发任务也在快速上行。单看某一个 benchmark 可能有噪音,但多个任务面一起被打穿,说明前沿能力还在继续进步,公开能力的扩散速度也越来越快。

这是快世界最强的证据:模型能力不只是在聊天、写代码、做题上进步,也开始进入 AI 研发本身。复现实验、优化训练代码、跑 benchmark,这些事情反馈更短,一旦 agent 能稳定参与,能力曲线可能继续变陡。
这不是说模型公司没有价值。领先者真正花时间的地方,常常不是最后那个分数,而是前面大量试错:数据怎么洗、agent loop 怎么跑、工具怎么接、失败怎么恢复、用户怎么验收。等 recipe 被行业看懂,后来者追模型会更快;但真正进入工作流的经验,不会同样快地复制。
快世界不只是模型分数。更重要的是,agent 正在改变工作循环本身:人不再每一步都卡在 loop 里,机器开始自己跑循环。换句话说,AI 开始把工作从人速推向机器速。
Agent:人从执行者变成管理者
Agent 和 chatbot 最大的差别,不是回答更长,而是人不再卡在每一个 loop 里。Copilot / Chat 时代,人要不断 prompt、read、再 prompt;agent 时代,人定义目标,agent 自己拆任务、调用工具、检查结果,最后跑到一个可验收的结果。

这张图好在,它没有把 agent 讲成一个更聪明的聊天框,而是讲成劳动组织方式的变化。所谓 labor is no longer human-limited,不是人不重要了,而是人的瓶颈从执行转到管理:定义目标、设置边界、验收结果。图里“1 analyst helping you”到“1,000 analysts working 24/7”当然有夸张成分,但方向是对的:工作不再完全受制于人的打字速度和 check-in 频率。
也正因为这样,agent 的变化会同时落在两张账上:一张是生产力账,一张是基础设施账。工作循环从人速变成机器速,token、上下文、测试、工具调用都会被放大。有个代表性细节:Anthropic 现在的 compute 紧张程度,比一年前更紧,不是更松。
原因不只是用户多了。token 消费模式本身变了:

这句话解释了很多账。一个 coding agent 做真实任务,会持续读文件(一个中型项目几万行代码就是几十万 token)、写代码、跑测试、修错、总结、再读上下文。复杂任务消耗几百万 token 不稀奇;chat 时代一次对话通常只有几千到几万 token。所以 $200/月订阅对重度 agent 用户其实是补贴,真实推理成本可能是几倍甚至十几倍。另一边,长期运行的 agent 需要记忆、上下文、调度和工具调用,负载也会从 GPU 扩散到 memory、CPU、storage 和网络。
所以,更直观的不是“用户数”,而是 token 曲线。Coatue 估算 OpenAI + Anthropic + Gemini API 的年化 token,从 2023 年几乎贴地,拉到 2025 年底约 16.4K trillion,并在 2026 年继续上行。这里的重点不是精确到每个点,而是斜率:agent 把调用频次从人速推到机器速。

Coatue:API token 消耗已经从人类聊天速度,进入 agent 工作流驱动的更陡斜率
这也解释了为什么 capex 还在继续上修。BofA 四月底报告给出的 CY27 hyperscaler capex 路径是 $1Tn,CY26 已经是 $700B+;Google 1Q26 财报披露 Cloud backlog 接近翻倍到 $460B+,Direct API Gemini token 16B/分钟、季度环比 +60%;Microsoft AI sales 年化 $37B+、同比 +123%。背后的逻辑并不复杂:agent 是 relentless 的,它持续吞 token,而 token 最后会落到硬件需求上。
再看负载结构:推理正在变得比训练更重。两年前业内估算训练占 AI compute 的 70-80%,推理 20-30%;现在很多 hyperscaler 的负载已经反过来。这个结构性变化对存储链尤其有意义:训练需要 HBM,推理也需要 HBM,但更需要 NAND/eSSD 来存 KV cache、模型 checkpoint、用户上下文。Citi 在四月报告里说 NAND CY26 ASP 同比 +172%、SSD 段位 +242%,这不像普通周期波动,更像 agent 时代的存储 TCO 重构。
我们更愿意把这轮 capex 看成“推理工厂”的扩建。Agent 把推理变成持续运行的工作负载。数据中心也会从“训练集群”继续演化成“训练 + 推理 + 存储 + 网络”的综合系统。GPU / ASIC 仍是核心,但瓶颈会同时扩散到 HBM、NAND / eSSD、数据中心网络、光通信、EDA 和测试。训练时代主要买的是峰值算力;agent 时代还要买上下文、缓存、调度、可靠性和低延迟。也就是说,capex 不是简单多买几张卡,而是在为更长任务、更高并发、更低错误率重做整套基础设施。
快世界的下一步,是任务上移。模型从做题、补全代码,走向更长、更完整的工作;但任务越往上,反馈也会越慢。
任务上移:从 E4 到 E5
Coding agent 最容易把“模型能力”和“工作能力”分开观察。Meta 工程师 level 是一个好参照。
如果用 Meta 的工程师 level 来看,E3 是新人,E4 能独立交付 feature,E5 能拿一个独立项目往前推,E6 开始定义方向、带几个 E5。Google、Amazon 的 level 体系叫法不同,但含义接近。“现在 coding agent 的水平,我觉得是一个很高的 L4——强 E4,”BY 说,“但要跳到 E5,还有距离。”
从 E4 到 E5,不是智力差距。更准确的类比,是一个聪明人从学校进入职场:

从 E4 到 E5,缺的不是 IQ,是职场训练。E5 要能主动判断该做什么,要记得项目历史,要理解业务约束,要对结果负责,还要有从大量反馈里磨出来的 taste。这些都不是 benchmark 分数能直接测出来的。

AI 已是强 E4,但跳到 E5 需要的不是更聪明,是更深的“职场训练”
难点在于,项目级工作的反馈周期太长。一个 feature 写得对不对,几分钟就能验证;一个 project 的方向对不对,可能要等几个月。模型在长任务里也会“压缩”需求,把 100 个要求压成前 20 个重点,后面的细节慢慢丢掉。上下文窗口变长有帮助,但不能替代真实工作环境。
从 E4 到 E5,不能只等模型“再聪明一点”。需要外部记忆、任务追踪、文件规则、技能库、验证 checklist,也就是前面说的 harness。谁先把这套工作环境做扎实,谁就更可能定义下一代 coding agent。
Jack Clark 把这个问题推得更远。他在 Import AI 455 里判断,如果 AI 研发里的多个 benchmark 继续同时上行,recursive self-improvement 可能在 2028 前后变成真实情景。60% 这个概率可以打折看,但问题已经很具体:AI 能独立工作的任务跨度,到底在多快变长?

METR(Model Evaluation & Threat Research)的任务时长指标更直接:AI 系统在一组任务上达到 50% 可靠性时,这些任务对应的“熟练人类完成时间”。
METR 数据:AI 任务时间跨度从 30 秒到 12 小时只用了 4 年。如果趋势延续,2026 年底可能到 100 小时(~两周连续工作),这正是 E5 / 真正 project-level 工作的时间尺度
如果这条曲线延续,BY 说的“E4 到 E5 还有距离”,可能不是 3-5 年,而是 12-18 个月。Ajeya Cotra(METR 研究员)认为,2026 年底 AI 系统完成“100 小时人类工作”不是离谱假设。100 小时大概就是一个 E5 工程师拿到独立 project 后,从需求到 MVP 的时间尺度。Cursor、Devin、Codex CLI 这半年爆发,是在把“独立工作几个小时”的能力产品化;当任务时长从小时变成天、再变成周,产品形态还会变一次。
模型公司和云厂商继续加码,赌的是任务跨度跃迁。只要任务跨度真的从“几小时”推到“几天、几周”,AI 就不再只是一个 chatbot 订阅,而是在进入软件开发、数据分析、客服、内部运营,甚至 R&D 的劳动力替代和增强市场。今天很多推理成本看起来很贵,资本仍然愿意忍,是因为它押的是后面那层价值:当 AI 能稳定完成 project-level 工作,ARPU 和可服务市场都可能重新定价。

我们不把这条 $2T ARR 路径当 base case。它把 Anthropic 的 run-rate ARR 和 Alphabet 的 GAAP revenue 放在同一张图里,本身就需要打折看;从算力供给、企业采购节奏、gross margin 到竞争格局,中间也有很多约束。但市场讨论这种数字,看的是“可自动化工作”的入口,而不是多卖一点 chatbot。云厂商今天的 capex 看起来像军备竞赛,本质上也是在买这个期权。
反馈环决定兑现顺序
任务跨度变长以后,下一层问题是:哪类工作能先转成生产力?答案通常不是“最宏大”的任务,而是反馈最短的任务。真正决定 AI 先在哪里变成生产力的是反馈环。
Coding 的反馈环天然短。模型写完代码,可以立刻编译、测试、运行、看 diff、看错误日志,几分钟内知道自己错在哪里,然后修。机器内部就能闭合“假设-验证”循环,不需要等用户、等市场、等老板。
反馈越短,AI 越容易进步,也越容易商业化。
很多企业场景慢,不是模型不够聪明,而是没有这么清楚、这么密的反馈。产品、战略、组织管理的反馈周期是周、月、季,噪音很大,归因也很难。
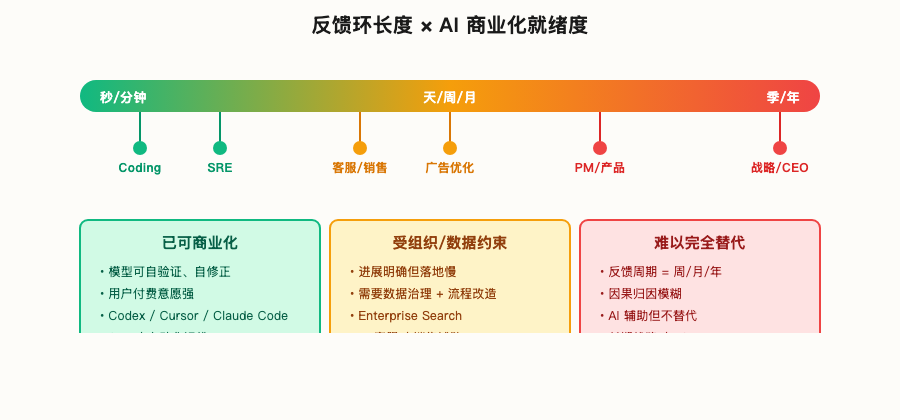
反馈环越短,AI 越早进入经营验证
放到业务场景里,短反馈环的工作流会先跑出来:客户支持工单、SRE on-call、代码 review、合同模板填充、保险理赔初审。反馈很长的工作——市场战略、组织设计、长周期决策——AI 可以辅助,但要完全替代还很远。
AI 研发本身,可能就是反馈环最短的工作流之一。如果 AI 能参与训练代码优化、实验复现、benchmark 提升和模型微调,它得到的反馈不是几年后的组织结果,而是几分钟、几小时后的 loss、speedup、score。
Clark 在 Import AI 455 里列过一个很具体的例子:Anthropic 内部让 AI 优化 CPU-only 小型语言模型训练实现。过去一年,AI 从 2.9x 加速走到 52x;同类任务,人类研究员通常需要 4-8 小时才能做到 4x。这还不是“AI 已经会自己造 AI”,但最短反馈环会最先自我加速。
如果这条路径延续,模型迭代、harness 部署和算力需求都会被压缩时间表。AI 研发本身可能先进入自我加速,capex 也要换一种读法:不能只看训练需求,还要看 agent 推理需求。
下半场:现实的慢世界
到这里,快世界已经很清楚:模型在变强,agent 在把工作循环机器化,AI 研发本身也可能自我加速。真正的分歧不在“AI 会不会继续进步”,而在现实世界能不能接住这些进步。
慢世界:同一个模型,为什么效果差很多
进入真实组织以后,问题就不再只是模型够不够聪明,而是这套能力由什么承载。Jack 讲的是能力斜率;我们更想知道,这条斜率撞到真实工作流时,哪些东西会变成壁垒。所以,落到公司层面,我们会更重视 harness。这个词中文不好翻,硬翻会别扭。其实可以简单理解成:模型进入工作现场时,外面那一整套工具、规则和验收机制。
最简单的区别是:你把同一个模型单独打开,让它回答“帮我改这段代码”,是一种效果;把它放进真实 repo 里,让它能读文件、跑测试、保留计划、失败后自己重试、最后把关键判断交还给人,就是另一种效果。前者是模型能力,后者才更接近工作能力。
AI 生产力不是模型自己“长出来”的,而是一层层叠出来的。底层是模型;往上是 harness,决定模型能不能稳定干活;再往上是场景数据,决定它知不知道“我们这里”怎么干;最上面是组织流程,决定它做出来的东西能不能被采用、被验收、进入 P&L。越往上,越接近真实 ROI,也越不容易被复制。
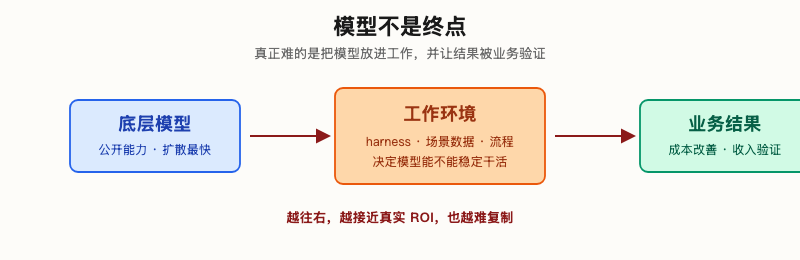
模型只是起点;真正难的是把它放进工作环境,并让结果进入业务
这件事在软件历史里并不陌生。云计算不是靠某一台 VM 留住客户,而是靠存储、数据库、权限、监控、计费和运维流程绑在一起。数据库也不是 SQL 语法本身有多难迁移,而是业务系统、数据模型、报表和权限沉进去以后,迁移成本才变高。
AI 也是这个结构。真正有粘性的不是“用了哪家模型”,而是“模型被装进了什么环境”。代码风格、业务规则、权限体系、数据治理和验收标准,决定了模型能不能稳定产出。只是接一个外部 API,没有自己的 harness 和场景数据,最后很容易留不住价值。
能力增长,不等于收入增长
用 BEDROCK 的“快世界 / 慢世界”框架看,AI 内部是快世界,现实组织是慢世界。模型能力可以按周、按月迭代,但客户验收、预算审批、数据治理、组织流程、用户习惯,往往按季度甚至按年变化。
内部能力翻倍,不等于外部收入翻倍。外部世界接不住,能力会先卡在验收、流程和预算里。
Coding 离 AI 的快世界更近,反馈可以机器化验证。企业 AI、广告收入和 Physical AI 则要穿过现实的慢世界。AI 能力增长和收入增长之间,隔着一层现实摩擦。

能力提升发生在 AI 的快世界,收入验证经常卡在现实的慢世界
Meta:生产力先到成本端
AI 的快世界和现实的慢世界,最容易在 Meta 身上看清楚。如果 AI 把 Meta 工程师生产力翻倍,Meta 收入是不是也会翻倍?
关键在于:“Meta 在 AI 上面提高的模型能力,并不是 bottleneck by productivity. It is bottleneck by experiments that can run.” 换成业务语言就是:Meta 的瓶颈不在工程师能写多少代码,而在它一年能跑多少个真实的 A/B 实验。
Meta 卡在哪里?先卡在广告主预算的总盘子——市场就那么大,不会因为模型变聪明就突然多出来。也卡在用户注意力——每个人一天就 24 小时,AI 变不出来。
更关键的是实验容量。A/B test 需要真实流量、最低人群规模、足够时间;Meta 的总流量虽大,却要被几百个团队的几千个实验切分,真正能分给一个新功能的“实验份额”是有限的。再往后,还有产品体验阈值、隐私监管、反垄断诉讼和 TikTok 竞争。
在 Meta,AI 的影响会先体现在成本端。同样的人能跑更多项目,OpEx 受益,利润率先扩张。要影响收入端,需要 AI 真的造出新的产品形态、新的广告库存、新的付费意愿——而这些都是慢世界的事,周期可能是几年。这和 Meta 过去几个季度的披露也一致:capex 持续上修(2026 年 $125-145B),收入 growth 维持高个位数到 +15%,AI 真正在做的事是让运营效率上一个台阶,而不是让收入曲线突然陡峭起来。
企业 AI:workflow 才是落点
硬件之外,企业端真正要改的是 workflow。很多公司一开始把问题问窄了:不是“买一个 GPT 接 API,让它替我做 X”,而是把工作流从“人主导”改成“AI 执行 + 人验收”。说到底,预算最终会流向 workflow 重构,而不是 API wrapper。
这不是买软件,而是改组织。公司要重新梳理流程,找出能被 AI 接管或加速的环节,建立自己的 skill 库、prompt 模板、知识库和工具调用规则,把重复工作交给 agent,再设计验收机制和 human oversight。Manager 的职责也会变:从管人,变成管目标、管系统、管验收。
这会分化出两类公司。第一类像咨询交付:帮客户梳理流程、接系统、做定制,收入可以增长,但每个项目都很重。第二类更像平台:把一次次部署里沉淀下来的工作流、数据 schema、权限规则和验收机制抽象成可复用产品。后者才更接近“把 AI 装进组织”的长期形态。
Palantir 是一个典型例子。它不一定拥有最强模型,但它有客户关系、数据系统、合规体系和私有部署能力。政府、军工、能源这类场景最难的不是接一个 API,而是让 AI 进入已有系统、权限和责任链。谁能完成这件事,谁就更接近真实生产力。
离软件反馈环越远,中间约束越多,AI 就越不能直接外推成生产力。Physical AI 是最典型的例子:模型能力只是其中一层,真正难的是系统集成。
Physical AI:慢在系统集成
再往慢世界走一步,就到 Physical AI。对这一块,判断需要更克制:Optimus、Figure 这些公司进展很快,但智力侧(LLM 大脑)ready,不等于系统 ready。
所以问题不是“body ready 了吗”,而是:什么叫 body is ready?

Robotaxi 是更好理解的类比。它相对人形机器人,任务边界其实更窄:车只需要在道路上行驶,不需要开门、拿东西、爬楼梯。但安全性、长尾场景、监管和公众信任,把它牢牢拽进慢世界。2019 年 Tesla Autonomy Day 上,马斯克说 2020 年会有上百万辆 Tesla robotaxi;现实走到今天,robotaxi 的推进仍然是城市、区域、天气、监管一点点放开。这里的差距,不是一句“模型不够聪明”能解释的。
完美的视觉模型加完美的车,不等于自动驾驶。关键是 sensor、control、decision、safety 这一整套端到端集成。机器人也是一样:感知、控制、动作规划、反馈延迟、软硬件协同,任何一项掉链子,就算大脑再聪明都白搭。
这正是机器人学几十年来的“Moravec 悖论”——计算机能轻松做人类觉得难的事(下棋、解微积分),但人类觉得简单的事(拿起一个鸡蛋、走过一片不平地面)对机器人来说极其困难。
Boston Dynamics 从 1992 年成立到推出第一台商业化产品 Spot 是 2019 年,整整 27 年;Stretch 商业化是 2022 年。这不是因为团队不够强,是物理世界的复杂度本来就需要这么久。最近 Physical Intelligence、Figure、1X 这些新一代公司虽然 demo 看起来惊艳,但从 demo 到能在客户工厂稳定运行 1000 小时,中间的路径仍然漫长。
这不是看空 physical AI。集成一旦突破,进展会突然加速;但现在还没到可验证商业化阶段。和 coding 不同,机器人要同时解决身体、感知、控制、安全和场景数据,反馈也很慢。它会是大机会,但不是把 LLM 大脑装上去就结束。
最后回到 BEDROCK 的主判断:AI 的分析重心要上移。过去两年,我们很容易追着 benchmark 跑;但在 AI 的快世界撞上现实的慢世界之后,更该问的是三件事:反馈环有多短,堆栈有多深,组织能不能吃下去。模型分数会被追平,harness、场景数据、组织流程、客户关系不会那么快被追平。
所以,我们反而不太想纠结“AGI moment 是哪一天”。事实上,人类历史里,很少有技术以今天 AI 这样的速度,同时改写模型能力、软件开发、资本开支和组织流程。如果所谓 singularity 指的是能力曲线变陡、反馈环变短、生产方式被重新组织,那它不是某个未来日期,而是我们已经身处其中的状态。
No singulation, all singularity.其实,我们不需要等待一个奇点时刻,因为已经身处其中。





留言