
当摩尔定律只剩一半功劳- “τ” 定律下的AI infra 投研框架
- BedRock

- 2天前
- 讀畢需時 4 分鐘
已更新:2小时前
“For modern AI workloads, data movement is as critical as computation itself” -Tingbo He, Huawei
刨除非市场化的因素和色彩,华为的τ定律可以和老黄的extreme co-design理解为同一回事儿:在AI对计算需求指数级大爆发的背景下,通过微缩提升晶体管密度,对每单位算力的成本提升已经有限了,未来需要先进封装、PCB、柜内外互联、甚至电源升级等等系统级的提升来大幅提升效率和降低成本。
英伟达其实早已经不是在单纯的设计芯片了,已经覆盖各类芯片的链接方式、机柜内外甚至整个数据中心的电源和液冷的设计,来提升计算效率
华为用一种更加振奋人心的方式讲了这件事情,解释了微缩技术做的事情本质就是0和1的信号传输速度提升,而信号传输速度可以通过先进封装等/光互联等方式,来绕过/淡化被卡脖子的微缩技术
两家公司用非常不一样的方式表达了同样的事情。用模糊的数字表达:假设摩尔定律 / 微缩技术是推动世界数字化和计算成本下降~ 90%的功劳;在AI的背景下,摩尔定律 / 微缩技术可能只占 ~50% 的功劳
翻译成投资术语:万亿级别的AI capex下,算力之外的很多核心环节,尤其链接,占AI capex占比提升是较确定的,会产生很多结构性机会
τ定律的文章中有一个很好的概括公式:信号的传速效率,不光是通过晶体管技术,而是通过circuit电路(比如提到混合键合),chip芯片,以及system系统(比如提到NPO 和 UB传输协议)等等各种其他方面的提升

Source: A Time Scaling Theory for Multi-Layer Electronic Systems
从投资角度我们也有类似的框架,就是在整体的AI数据中心建设当中,找到所谓的最能减少“τ”值的瓶颈环节、推动这些环节技术进步的玩家,再从中挑选竞争格局相对好、技术替代风险低的环节。
可以从信号传输的距离,大致分为四个环节,以及对应的“τ”定律框架上:先进封装,PCB,Scale up&Scale out

其中每个环节都在供需两端发生着非常大的变化,随便聊聊我们看到的一些非常有趣的方向,不代表任何投资观点
先进封装:封装行业的“台积电时刻”?
先进封装,尤其混合键合hybrid bonding 是τ定律中提到最多的一个技术。目前的主流的先进封装是 CoWoS(2.5D 封装),把计算芯片和 HBM 共同摆在 silicon interposer 之上,就像在地面上架起一条高速公路,信号必须横向行驶才能连通两端;而混合键合更像直接在原地起楼,通过 Cu-Cu 直接铜铜键合把 die 与 die 在垂直方向上对接,信号像坐电梯一样直上直下,几乎不需要“行驶”。距离对比是颠覆性的:CoWoS 横向 1-10 毫米,hybrid bonding 垂直只有 0.01-0.1 毫米,缩短了上百倍;每平方毫米能产生的链接的线的密度,也从 ~1000 个的级别上升到万/十万的级别
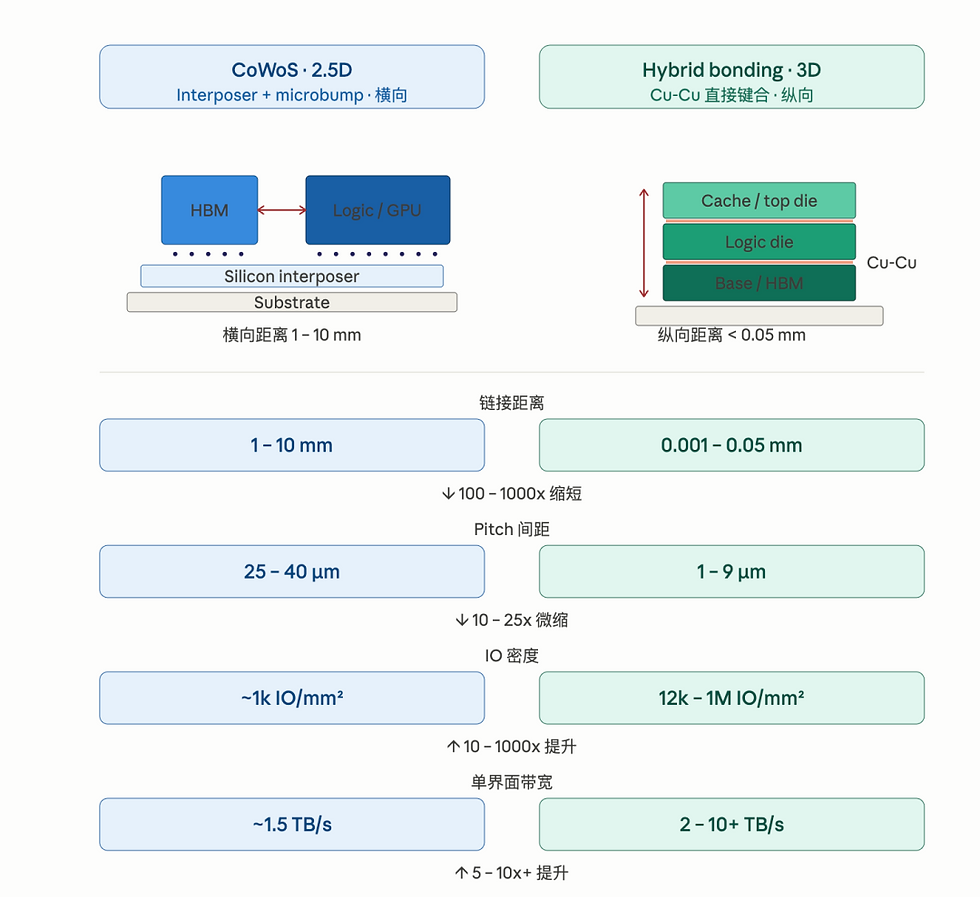
混合键合设备需要的对准精度已经进入了纳米级别(亚 100nm),与半导体前道光刻的对位精度同一量级,所需的洁净室等级也已经接近 fab。有趣的不光是这个技术路线和这个设备,而是它能代表的先进封装整个行业的变化。就像半导体代工厂,在成熟制程上是一门竞争相对激烈的生意,但先进制程中竞争格局明显分化,封装厂也是有了这样的苗头:一个芯片的封装任务从只需要一台封装设备,到需要一条20多台机器的昂贵产线,和每一个环节的knowhow。
PCB :对上游材料物理极限的再一次冲刺
最近大摩的一篇研报非常火,其中提及了PCB在Vera Rubin中机柜UE 占比提升仅次于存储。有一个需要理解的底层物理知识,AI所需要的信号,在 ~20mm 以内(也就是 GPU 封装内部、substrate 上)是可以“并行走线”,而在这个范围外,也就是当信号传输到了PCB,信号需要“串行走线”

这个所带来的是对PCB上的铜线的数量 * 每条线能承担的速率要求的指数级提升,对应到PCB产业当中,就是单个PCB的层数和材料。PCB UE 提升背后的逻辑就是信号传输需求快于对算力的需求的逻辑
这个领域中也有非常多有意思的环节和公司,最令人感慨的是材料环节,看到了AI需求驱动下人类对各种基础材料的物理极限的再一次冲刺
比如铜箔,因为信号是在铜箔表面走的,越粗糙,上上下下走的路就越多,越光滑,走的路越少,所以现在大家要把铜箔的光滑度做到 0.5微米以下.....没错,又是一个纳米级别的环节

Source: Mitsui Kinzoku
Scale up / scale out :"光进铜退"
现在才进入到大家提到AI链接会直接想到的板块,scale up和scale out
这部分的趋势也是逃不过物理定律的,速率上升,以铜为介质能高效传输的距离越来越短,信号就要换一个介质了,从铜变成光。

Source: Corning
但这部分中的结构性的投研确认让人头疼:光模块/LPO/NPO/CPO/OCS等等技术路线,每个技术路线当中还有不一样的解决方案(如光模块的硅光 vs EML vs TFLN, OCS的MEMS vs硅光波导...) 。重点需要找一些技术迭代风险小,能长期存在的环节
Scale across / DCI :高带宽需求溢出单个数据中心
以目前数据中心建设的方案,平均每GPU的scale across的带宽还非常低,但这部分的带宽,无论是因为十万卡集群的训练需求,还是agentic workflow带来的对离客户更近的推理数据中心需求,在未来是有可能占比快速提升
可以参考最近刚发布的文章:(此处插入之前发布的DCI文章)

写在最后:
AI链接确实是一个较为复杂且变化极快的行业,且各个环节边界开始模糊,各方玩家跨界竞争,各个环节相互替代,不用AI,已经完全做不了AI领域的投资了。做这个行业的投研,可能是一个以AI为基础重新打造投研工作流最好的 use case



留言